原创,总结及翻译,转载请注明出处
在本人发于14年初的原帖基础上稍作修改,主要来源为Anandtech。
目录:
本文为在Anandtech上发现的名为The Bulldozer Aftermath: Delving Even Deeper的文章
文章主要介绍了推土机架构在服务器方面的特性。
前言
从农企AMD发布推土机架构,并以其超群的性能震惊整个硬件发烧友社区已经有几个月了。然而人们的意见大相径庭,从“服务器测试已经不容置疑,它们就是一坨翔。”到“2011年最佳服务器CPU”,你至少可以说关于AMD推土机架构的讨论一时甚嚣尘上。(stirred up a lot of dust)
现在,尘埃落定,推土机芯片目前占Opteron处理器超过一半的出货量和收入。 在AMD的财务分析师日 (2012年2月2日),发布了新的基于改进的推土机架构“打桩机”的,代号为“阿布扎比”的芯片,用来取代目前的顶级服务器芯片“interlagos”。 AMD显然是致力于改进“推土机”架构的方向:在同等功耗下塞进尽可能多的核心( fitting as many cores as possible into a certain power envelope ),以提高线程的吞吐量,同时试图保持较为平衡的单线程性能(hold the line” on single-threaded performance.)
从理论上讲,新的16核心interlagos应该有大约33%的提升(在大多数多线程应用程序中)。很不幸,现实情况没有那么乐观:在许多高度多线程服务器应用程序,如OLAP数据库和虚拟化,新的皓龙6200未能让人印象深刻,并且只比它的前辈12核Magny-Cours只快几个百分点。甚至有时候老的Opteron会更快。
有些人,包括AMD公司内部人士透露,指责GF不提供更高的时钟的产品。 【GF果然大坑】当然,Interlagos的目标频率应该接近3Ghz而不是2.3Ghz。但是,这并不能解释为什么多余的整数内核没有用。 归功于33%额外的核心,农企许诺最多有50% 的提升,但我们最多得到了20%。
Interlagos结合了较低的单线程性能,未能在高度线程化应用中真正超越上一代Magny-Cours,满载下相对较高的功耗耗,而事实上,推土机架构是专为高时脉速度设计的。很多人似曾相识:这是AMD版本的奔腾四?
我们的读者之一, “Iketh,代表了我们很多读者的意见:
“当我在读这篇文章时,一个想法一直在我的脑海里–为什么AMD要重塑奔腾四?我只是不明白这一点。”
绰号“Clagmaster”另一位读者评论说:
“在我看来这么复杂的核心还没有做好优化,以充分发挥其潜力。当AMD推出该核心的后期步进,降低功耗并提高的时钟频率时,我期待能有更好的性能。”
虽然已经有不少人尝试了解推土机到底是怎么一回事,我们觉得很多问题仍然没有答案。 由于这种架构是AMD的服务器,工作站和笔记本电脑未来的基础(Trinity也是基于改进的推土机核心“打桩机”),我们来深♂入探讨一下这有趣的问题。难道AMD又采取了这种错误的架构? 如果没有,改进“推土机”容易解决吗?
我们决定深入研究SAP和SPEC CPU2006的测试结果,并分析我们自己的基准测试。 通过分析数据,并与我们已知的关于AMD推土机和Intel的Sandy Bridge的信息相结合,试图解决这一难题。
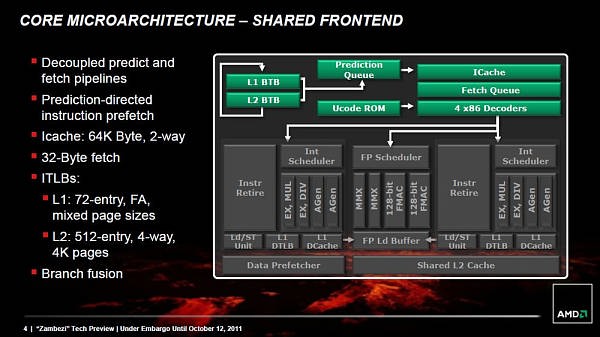
【前端:分支预测】
推土机的分支预测单元已经在很多文章中被描述。 多数业内人士都认为推土机的分支预测器是一个K10的多层次的改进版。 更好的分支预测可能会降低5%的分支预测错误率,但并这不是故事的结束。 下面是各种CPU架构的分支预测功能的简要总结。

上面的数字显示最小分支预测错误惩罚,而事实是,Bulldozer架构的分支预测错误惩罚比上一代产品高66%。 这意味着,推土机的分支预测必须比K10多正确预测40%来补偿(在同样的主频下)。不幸的是,那种大规模的分支预测的改进几乎是不可能实现的。
不少人批评推土机是AMD版本的英特尔奔腾4:它有很长的管线,具有很高的分支预测错误的惩罚,它为它无法达到的高主频而生。 上表似乎加强了这种印象,但推土机和NetBurst架构之间的相似性只是表面上的(superficial)。
推土机芯片的最小分支预测惩罚确实和奔腾四是在相同的范围内。 然而,在奔腾四上分支预测的最高惩罚可以达到恐怖的100周期以上,而推土机却低了不少。 在最常见的情况,推土机的分支预测错误处罚将低于30个循环。
其次,Pentium 4的流水线为28(willamette)至39(prescott)周期。 推土机的管道深,但它不是那么深。 确切的数目未知【其实现在已经揭晓,是18级】,但它低于20级。 真的,推土机的管线长度并不比英特尔的Nehalem或Sandy Bridge架构(约16至19级)高多少。 最大的区别是,在Sandy Bridge中引入的μop缓存(约6KB)【micro op微指令缓存,源自奔腾四的高速追踪缓存】,可以减少典型的分支误预测到14个周期。 只有当该指令不在μop缓存内,并且必须从L1数据缓存中取出时,分支误预测惩罚才会增加至约17个周期。 所以平均来说,即使推土机的和Sandy Bridge的分支预测器的效率相同的,Sandy Bridge的分支预测失误也会少很多。【这要归功于奔腾四时代积淀的优秀的分支预测技术,简单来说酷睿架构就是结合了P6架构的短流水和奔腾四分支预测的产物,所以可见奔腾四也不是一无是处】
【前端:共享解码器】
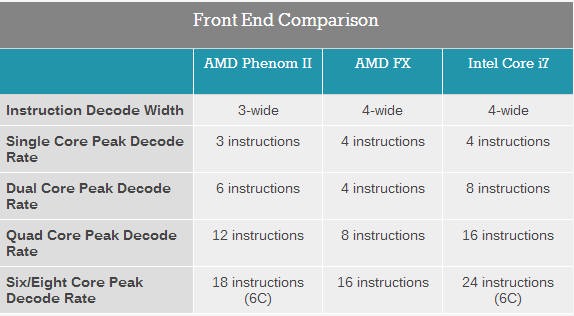
不少评论,其中包括我们自己也指出,在推土机中,两个整数核心共享四个解码器,而在旧的“K10”架构两个整数核心分别有三个解码器。 两个K10核心从而有六个解码器,两个Bulldozer核心只有四个。 考虑到x86 ISA的复杂性导致大量耗电的解码器(power hungry decoders),减少三分之一的耗电量(如双核配备四个解码器,而不是六个),同时导致少许单线程性能损失来降低功耗。如果你想把16个整数核心保持在115W功耗,这是一个很好的交易【减少解码器,拿少许性能损失来降低功耗,以放进更多的核心】。所以推土机没有使用48个解码器【按照K10标准,每核心3解码,Interlagos有16核心,就是16×3=48个】,而是尝试只用32个【八模块十六核心,每模块四核4个,就是8×4=32个】
两个整数核心之间共享四个解码器在单线程性能上的劣势可以被预解码阶段的X86融合(test+jump and CMP +jump,英特尔叫做微指令融合)。 英特尔早在2006年酷睿架构推出时,就首次推出了微指令融合。
不过农企在Intel之后把这种X86融合引入了推土机。X86融合的结果是,自从Nehalem,Intel所有CPU的X86-64解码宽度增加到了5!而X86融合并不会增推土机模块的最大解码宽度。
这绝不是一件小事,因为此类融合可能每十个X86指令就发生一次。
那么,为什么AMD让这个能提高提高有效解码率的机会白白流走,即使在某些应用中会产生瓶颈? 最有可能的原因是,在解码之前这样做增加了芯片的复杂性,因此增加了电力消耗。
0即使AMD版本的X86融合不会增加解码的带宽,它仍然提供了优点:
①增加带宽调度
②减少调度队列占用
③更快的分支预测错误恢复
前两个提高性能,而无需任何额外的(或极少)的功耗,最后一个提高性能并降低功耗。 在相同功耗下,农企偏向于多核心,而不是更高的解码带宽和单线程性能。
在Hardware.fr的比较测试中,一个四模块推土机,如果每个模块只打开一个核心,在轻度多线程游戏要快3-5%。表明前端可能是一些高IPC负载的瓶颈,但是这个瓶颈并不明显。
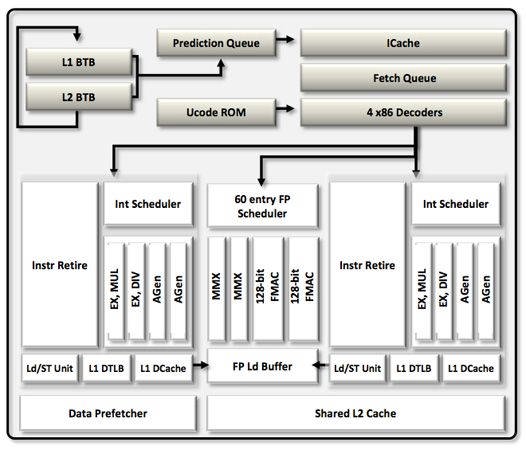
AG0和AG1执行单元减少了CALL和LEA指令的延迟,但单位时钟周期内,推土机模块内每个整数核心最大吞吐量仅为两条整数指令。 只有当一个融合分支进入EX0,另一个整数指令进入EX1时,吞吐量才会略高于K10。
所以,推土机的整数核心没周期能执行的整数指令比K10少(2vs3)。然而 这并不意味着推土机整数核心的速度就要慢三分之一。 推土机的整数核心更小,也更灵活。农企取消了每通道专用的8Enrty调度器,用一个更大的40Entry调度器取代了它。 这意味着,推土机更擅长从低IPC(每周期指令数)的代码中提取ILP(指令级并行)。【众多测试都证明了农企推土机,打桩机以及压路机架构的低IPC】
一些整数密集型应用中,如果推土机最大整数吞吐量会慢下来的情况属实,整个程序就会慢下来。 这是一种“看情况”的回答。让我们来澄清一下:我们到底说的是什么样的应用程序。
【现状】
这也就不难解释为什么单线程性能略低的八核FX处理器并没有在很多桌面应用程序表现的很好。 例如,如果你比较一下6核的Core i7-3960X与四核酷睿i7-3820 ,有四个游戏并没有受益于额外的两个核心:文明V,孤岛危机,尘埃3和地铁2033。 在星际争霸2,魔兽世界,和战争黎明2,多出的50%核心数是最多带来了10%的性能提升。 换句话说,情况有所好转,但大多数游戏只对四核心优化。 此外,还有其他因素在起作用,我们已经知道星际争霸II是双核游戏,很可能是15MBL3提高了性能(酷睿i7-3820为10MB)
在服务器领域的很多情况难以解释。 皓龙6100 是或多或少能够跟上至强5600系列的。
然而,配备了更好的电源管理的至强5600在大多数应用中赢得了能耗比之战。(除了HPC应用)
皓龙6200【推土机系列】增添了一点性能,而且在中低负载功耗更低,所以它的能耗比比前辈更好。
然而至强E5粗来了,皓龙处理器的局势有了戏剧化的变化, 一个生动的例子是,VMware上只有皓龙6200的一个测试成绩,但它已被撤回 【自取其辱了?】。 如果12.77的得分接近真实成绩,我们需要四路AMD皓龙6726(2.3GHz)才能领先最好的双路 Xeon E5 15% (E5-2690,2.9GHz)
以下是实际的专业测试。

我们认为,所有这些应用都高度线程化而且有很好的扩展性。 尽管有高出33%的整数核心数,皓龙6276不能在OLAP,虚拟化和渲染基准中胜过Magny-Cours。 但是,推土机架构通过SAP和HPC应用程序约20%的性能提升证明了其承诺。
是什么让Bulldozer核心无法在OLAP基准和SAP中取胜? 我们现在对SAP以及OLAP基准进行一些有趣的细节分析,这样我们就可以更加深♂入。
【SAP S&D profiled】
在SAP S&D 2-Tier基准测试一直是我的最爱之一。 这可能是由供应商完成的服务器基准测试中最现实的标杆。 这是一个完全成熟的基于重关系性数据库的应用程序。 而且不要忘记,SAP是一个最成功的软件公司,是企业资源规划领域无可争议的市场领导者。

除了高水平的分析数字,相当多的细节浮出水面。 例如,把ROB(重排序缓存)从128(Westmere处理器)增加至168(Sandy Bridge)使得ROB延迟从10%降低到几乎没有。 把负载缓冲区从48增加到64,使得负载缓冲延迟降低到了之前的五分之一! 这清楚地表明,SAP在ROB和负载单元投入相当多的压力。现在大多数处理器的整数性能都可以满足这个程序,但是会被数据Load速度和乱序引擎隐藏延迟的能力所限制。【乱序引擎的主缓冲区是ROB】
进一步的数据证实了这一点。我的理解是Sandy Bridge的硬件预取器相比的Westmere / Nehalem处理器进行了一点改进了,但实际上SNB更智能的预取器能够把L2未命中率降低到不超过40%!
现在SNB在SPEC2006整数测试中,1000条指令中只有1到10条会L2未命中,而至强5600【Westmere架构】则会有40条未命中。
因此SAP中会有比一般程序更多的L2未命中率【HPC除外】,SNB中更好的预取器更好滴利用了额外带宽,降低了L1,L2未命中率。
对SAP的结论
该应用程序具有非常低的指令级并行(ILP),其结果是整数单元负载不高。
该应用程序有一个比较大的,但可以预读取的指令,它允许预取,以减少相关指令的缓存未命中率。
该应用程序有一个巨大的和随机的数据占用空间,构成重大压力的负荷子系统。 其结果是乱序引擎可以尽最大可能隐藏延迟,大ROB和负载缓冲则会有很大的帮助。 说明内存子系统延迟是主要问题。
与SAP应用程序具有高量的TLP(线程级平行度)的事实结合起来,你就会明白,这是非常适合超线程和集群多线程的应用程序。 超线程就是很好的一个例子。它带来了30%的性能提升。 SAP S&D的基准是一个CPU架构能否面对多个服务器或多个面向消费者的一个最好的例子。 服务器应用程序的与我们的笔记本和台式机的运行的软件有天壤之别。
推土机单核整数核心有限的执行资源并不会给SAP带来瓶颈。推土机已经大大提高了预读取能力,增大了乱序缓冲区,增加了33%的核心数量,我们期待推土机会比Magny-Cours至少快33%。因为SAP强调的是推土机的强项而不是软肋(低整数吞吐量)。
然而实际提升压根没有33%,更别说农企承诺的50%了
哼?哼?看来发现了些什么啊~
【SPEC2006整数测试】
E5是单位主频和单核心效率最高的。
让我们比较一下皓龙6276 (2.3GHz,拥有16核心的推土机)和皓龙6176的测试(2.3GHz的12核Magny-Cours)
从此可以看出推土机和K10的模式完全不同。
Libquantum,OMNETPP和MCF表现出高于核心数增长(33%)的性能提升。 这些基准表明,在某些情况下,推土机的IPC甚至高于K10。


我们还注意到,推土机有它的前身相比一些严重的缺点,在Perlbench,游戏AI(gobmk),国际象棋(Sjeng),和X264编码分中性能下降。 虽然一个新的架构未能在每一个测试中击败老架构的情况并不少见,但是增加了33%的核心数还不能克服IPC减少,并不是一个好的迹象。 如果我们试着去了解什么使这些软件与众不同,卡住了推土机。这反过来又可以帮助我们理解,是否小的调整可以帮助未来的Opteron处理器。
【放大SPEC2006结果:好的方面】
我们筛选出了推土机相对于K10提升在30%以上的测试。要记住推土机要在相同功耗下增加33%的核心数,同时把IPC保持在K10的95%左右。
其余的性能增长本应该由主频提升带来,但是实际上主频提升没能实现。【GF工艺问题】
为了研究架构,我们把主频都调到一致。

该Libquantum得分是最壮观的。 推土机得分2750,比K10快两倍,和2.2G的E5-2660的3310分差距也不是很大(15%)
乍一看,没有什么能够使Libquantum在推土机上运行速度这么快。 Libquantum含有高量的分支(27%),虽然推土机的分支预测已经有所改进,但更深的管线和更高的分支预测错误处罚可能会造成很多麻烦。 事实上,Perlbench(23%),Sjeng国际象棋(21%),和Gobmk(AI,21%)也为多分枝软件,而且推土机在这些测试中表现最差。幸运的是,Libquantum具有更容易预测的分支:libquantum具有最低的分支预测错误率。(每1000个指令小于六条)
我们都知道,推土机和Magny-Cours相比可以更好的处理Load/Store。 然而,libquantum具有最低的Load/Store数量(19%= 14%Load,5%Store)。 推土机改进的内存级并行不是正确的答案。 下表列出了SPEC CPU2006int的指令组合。

对于大多数CPU,Libquantum具有相对高的缓存未命中率,因为它使用的是32MB的数据,因此越大的缓存越有利。 8MB的L3与6MBL3相比有可能提高了一点性能,但推土机的主要原因是大幅提高的预读取。
据奥斯汀和微软的大学的研究人员,在libquantum中的预取请求是非常准确的。 如果您看看AMD自己的出版物,你会发现,有两个重大改进提高Bulldozer架构的单线程性能(相比以前的):改进的Turbo Core和大大改进的预读取。
接下来,让我们来看看优秀的MCF结果。 MCF是迄今为止最密集的内存SPEC CPU标杆在那里。 MCF的L1未命中率比一般测试高5倍,命中率低于70%! MCF对LLC【LastLevelCache,最后一级缓存】的未命中率是一般测试的八倍! 显然,MCF是从推土机大幅提高的L / S单元中受益的代表。
OMNETPP不是极端的,但是它的指令组合有52%的Load和Store,而且L2和最后一级缓存未命中率是其他测试的两倍。 而相比之下,MCF中,分支误预测的量要低得多,尽管它的分支预测比例同样高(20%)。 因此,在很大程度上,对内存子系统的低依赖性由更低的分支误预测率来补偿。 更准确地说:分支预测的量低了约3倍! 这最有可能解释了为什么推土机在OMNETPP相比在MCF中取得的进步更大。
【放大SPEC2006结果:失败之处】
在推土机表现好的SPEC CPU2006整数测试中得到了30%至117%的提升。 不幸的是,完整的基准套件只显示21%的提升(皓龙6276与6176相比)。 进一步的检查显示,在四项测试中出现了倒退。 在这些测试中倒退似乎很少(7-14%),但请记住,我们增加了33%的核心。 即使是很小的7%的倒退,意味着我们失去了先前的架构单线程性能的30%!

Perlbench主要使用L1和L2缓存,很少访问最后一级缓存,更不用说内存。 测试结果的一个提供高IPC的标杆:七年前发布的Core 2 Duo(“Merom”)的IPC是1.67,并和最新的英特尔处理器的1.9很接近。要注意的是,在SPEC2006测试套件中,h264ref和Perlbench都是顶级的IPC测试程序。
Sjeng(国际象棋)和Gobmk都是AI的子程序。 同样,IPC是比较高的(> 1),但其最重要的性能特点是,其中难预测的分支比例很高,是其他测试的两倍。
诚然,我们已经提出的证据仍然是间接的。 需要对所有新处理器进行一个非常长期且深入的分析才能真正确定是怎么回事,这超出了我们的时间预算:一种SPEC CPU测试运行就要消耗一整天。对三个不同测试的简短分析为我们提供了一些非常有趣的结果,这就是我们接下来要讨论的。
【IPC解析:到底怎么整的?】
我们把两个线程的IPC加在一起

如果你在至强E5上开启SMT(同步多线程),单核又会增加0.4 IPC。 这在一个以许多分支和负载SQL语句为主的基准中是很了不起的。
皓龙6200揭示了内部的一些信息。当启用模块内另一个整数核心,单线程性能有所下降。在Cinebench中这并不奇怪,因为它使用了大量的SSE浮点指令。一个模块启用单核心,这一个核心可以占用到全部的乱序浮点单元,而开启模块内的两个核心时则必须共享浮点单元。
但是在datamining基准中有其他的情况。如果启用另一个整数核心,单线程会下降18%。
启用同一模块的两个核心,比单核心性能提升了65%(2×0.71vs0.86),与农企所说的CMT80%提升低一些。看来共享资源会降低性能。
【缓存分析】
我们没花多久就找到了推土机开启CMT后单线程性能下降的可能原因:指令缓存。
7zip和Cinebench中的指令完美的适配了指令缓存,但是MS SQL Server 没有做到。
在最新的Intel CPU中,8路32KB的指令缓存显然不够大。而K10.5皓龙却做的很好,它的指令缓存未命中率要少40%。

推土机中2路64KB的指令缓存显然不是缓存两个线程的最佳选择。当开启一个模块的两个线程时,命中率从极佳的97%(单线程)降到了平庸的95%。
所以农企需要增加L1指令缓存的关联性,以确保这两个CMT线程不会互相妨碍。
让我们看看数据缓存。
为了控制模块的芯片面积,把L1数据缓存从64KB减少到16KB可能是必要的。
(一个推土机模块面积小于80m?,两个K10.5核心则是较好的115m? )
然而这减少伴随着了代价:数据缓存未命中率是以前的两倍。Intel的8路缓存确实好一些,但也不是很牛叉。

接着看看二级缓存。
老皓龙和至强较低的L2命中率使得它们看起来只是靠运气命中的,但那不是事。
不要忘了在Cinebench中,L1未命中率极低,所以大部分易于缓存的代码和数据已经存在。
至强5600中相对较高的L2未命中率是说在1%未命中L1的情况下,有44%会L2缓存未命中- 或者换句话说,几乎没有(0.44%)。 这些数据几乎被完美地缓存,并且数据缓存的命中率是99.99%。 大部分的L2未命中只是几个几乎不使用的指令。
在7-ZIP测试中,的皓龙6174的二级缓存比较糟糕的命中率也是如此。 与其他CPU相比,K10皓龙具有较高的L1数据缓存命中率,所以二级缓存较少访问。 L2命中率低不是老皓龙性能较低的原因。 这给我们分析的最后一个领域….
【在这里貌似把具有庞大L2的推土机忽略了…..那么大L2命中率还会低么】

【分支预测分析】
农企工程师在推土机中完全重新设计了分支预测单元。他们成功拉近了与在分支预测领域有些丰富经验的Intel的差距吗?让我们看看。
新皓龙的BPU【分支预测单元】至少和老皓龙做的一样好,有时还有明显改善。这是农企正确的又一个地方。
Intel的BPU在MYSQL中赢得很明显。

【缓存不是唯一的,但可能是主要的元凶】
大多数人指出,缓存的高延迟是推土机欠佳表现的理由,但推土机表现欠佳的真实原因要复杂得多。 首先,在大多数应用中,乱序处理器可以很容易地隐藏L1缓存四个周期的延迟。 英特尔三年前与Nehalem架构一起推出了4个周期延迟的L1缓存,而英特尔的工程师声称,仿真结果表明,3周期L1将只提升2-3%的性能 (在相同的主频下),这与更高主频提升空间带来的性能提升相比微不足道。
其次,一个专用的4路16KB缓存,虽然比较小,但不比Intel两个线程共享的8路32KB数据缓存差。 缓存还预测降低搜索的力量,所以推土机数据缓存的设计确实有它的优势。
SAP和Libquantum告诉我们,推土机的预读取工作的很好,L2缓存20循环的延迟在服务器和高性能计算应用中影响不大。 我们还注意到,大的2M L2的命中率比512KL2的K10高得多。 因此,虽然L2缓存的延迟不是一个优势,我们肯定怀疑,这是一个主要因素。
我们确实同意,因为大多数我们的分析显示,游戏和其他桌面应用程序对L2缓存延迟更加敏感。 这是所有的原因之一,毕竟这也是Nehalem并不比旧的Penryn的CPU快很多的原因。【参照E5450和i5 750同频性能】
低线程化的桌面程序在大的,低延迟的L2缓存运行最佳。 但对于服务器应用,我们发现比L2高速缓存更严重的问题。
【真正的不足之处:分支预测错误处罚和指令缓存命中率】
推土机是一种长流水线CPU,就像Sandy Bridge,但后者有一个μop缓存,可以减少提取指令和解码循环出现的分支预测错误处罚。 在SAP和SQL Server测试中低于预计的性能,加上SPEC2006整数测试中表现最差的几项测试,这些具有难预测分支的测试都说明,推土机的分支错误预测上有严重问题。【不是分支预测单元的问题】
我们的代码分析表明,AMD的工程师在分支预测单元上的工作做得很好:BPU肯定比以前AMD的设计更好。 问题是,推土机无法掩盖其过长的预测错误处罚,而Intel的Sandy Bridge却成功做到了这点。 这也解释了为什么AMD公司指出,在“打桩机”上,分支预测的改进只是轻微的(带来1%的性能提升)。 由于分支预测器越来越先进,各方面的调整不可能做太多。
AMD在不久的将来是否将采用μop缓存,这一点很值得期待,因为它会降低分支预测刑失败的惩罚,节省电能,降低对解码部分的压力。 它看起来能完美的匹配推土机这种架构。
另一个显著问题是,L1指令缓存似乎不与两个线程配合良好 。一旦我们在2路64KB L1指令缓存上运行两个线程,缓存未命中率会显著提高。 看起来缓存的关联性简直是太低了。 这是英特尔采用8路关联缓存来运行两个线程的原因。
【台式机,性能并不优先】
无论推土机目前怎么粗糙,如果你看的深入一点,这不是为了高IPC,分支密集型,轻度多线程应用程序设计的架构。 更高的时钟速度和Turbo的核心应该是为了发烧友打造的CPU。 该CPU应该在相同功耗下,提高20~30%的时钟速度,但最终它只能提供10%的提升,而且功耗稍高。
【服务器:仍有希望】
看完这篇文章,有一件事应该已经明确,那就是服务器应用程序拥有比SPEC CPU测试或工作站软件完全不同的需求。
他们被MLP限制,IPC更低,并且更具扩展性。 他们还配备了一个更大的内存,并且以高未命中率惩罚小容量的低延迟缓存。 【意思是说Intel的低延迟小缓存不占优】
因此,推土机延迟较高,但容量大的L2缓存,在好的预读取的帮助下会有合适的表现。
我们相信,对于整个专业IT领域,推土机的概念是掷地有声的。它做出的牺牲都是为了服务器方面,但是有四个主要的障碍:①指令缓存,②分支误预测惩罚,③主频上不去,这些都是使得推土机在服务器领域表现不佳的主要原因。【第四条没有….才怪在下面】
低主频的问题已经在打桩机上得到解决,这意味着阿布扎比可能是一个惊喜。农企曾经这么做了:2007年的Barcelona,起始频率是令人失望的2.0Ghz,单线程性能糟糕。而08年的改进版Shanghai主频提升到2.7G,缓存延迟降低了三倍。
至于第四个障碍,它在SNB中也有出现(程度更轻),我们的调查结论还没有准备好,所以还需要等待…….
全文完毕,使用了机翻然后人工校对润色,若有不通顺的地方请指出。



