原创,总结及翻译,转载请注明出处
在本人发于14年初的原帖基础上稍作修改,主要来源为Anandtech。
目录:
在Zen架构设计已经冻结,马上开始ES测试阶段的现在,很多人对于AMD的未来依然抱着不明朗的心态。AMD的Zen架构性能尚未见分晓,而光凭官方ppt已经无法说服人们了,因为人们已经被AMD的推土机架构坑了太久太久,以至于目前黑AMD,尤其是AMD的CPU成为了所谓的“政治正确”,黑了,你就对了,你就比别人高一头 — 无脑A黑大多是这样的想法。
然而曾几何时,推土机架构也和Zen一样,是被寄予厚望的孩子。想借着超前的CMT架构来和Intel的高端i7正面交锋。

那么,到底是为何导致推土机如此不给力?今天就带你深入了解AMD推土机架构,希望看完的各位都能够对推土机架构有个客观的评价,而不是无脑黑。
译者前言:推土机架构是农企AMD在K8架构以来,唯一一次真正意义上的架构革新。推土机架构大概在2007年开始计划,然后几次跳票,最终在2011年10月12日发布了第一代推土机架构处理器,因为GF不给力导致的跳票使得推土机进度大大延后,对手从Bloomfield/Lynnfield i7直接变成了SNB….
在2011年,对于多数游戏,多线程优化还是个笑话
押宝重度多线程的推土机/挖掘机在大多数单线程程序中大幅落后。
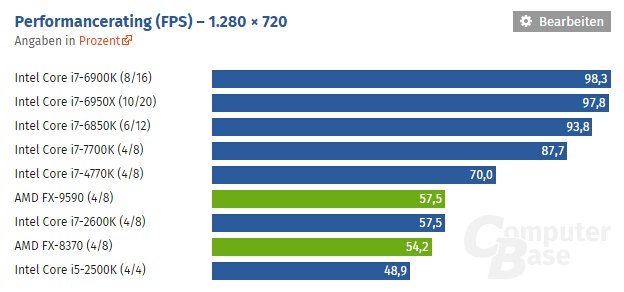
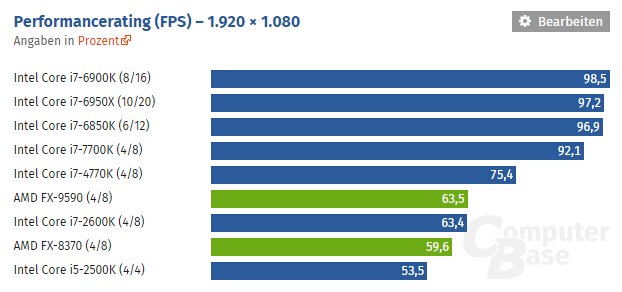
然而在6年后的2017年,多线程优化成为大趋势的现在,推土机/打桩机的优势才可以完全发挥,作为一个32nm SOI制程的老架构,能达到这样的性能说明,并不能简单地说推土机是个“失败的”架构。
当年,与众人的期待相比,备受瞩目的推土机并达到人们所期望的性能水平。
为此众多人士对推土机架构的褒贬不一,并且大多数以大炮村,大炮洋为代表的大众媒体对推土机架构的效率开展了各种炮轰。
从此农企AMD走上了推土机架构的不归路改进之路。
以下是AMD的农机系列路线图,这些架构在官方文档中统一被称为Family 15h,都是继续推土机架构并进行优化的产物。
可以跟明显的看出每一阶段的具体目标。
第一代:Bulldozer【推土机】,第一代模块化架构,①灵活的浮点单元,②支持128/256位 AVX,XOP,FMA4,这些已经实现√
第二代:Piledriver【打桩机】,提高架构IPC(即InstructionPerCycle,单位时钟循环执行指令数)和时钟频率,这些已经实现√
第三代:Steamroller【压路机】,更好的并行性(或者说多核效能),这些已经实现√,据测试IPC提高了15%左右
第四代:Excavator【挖掘机】,极大地提升性能,支持AVX3.2,TSX,DDR4等新特性,IPC提高15%
下面,就由楼主结合各方面资料,深♂入探究一下推土机系列架构的特性。

首先是Anandtech对推土机架构的评测

推土机被称为 AMD FX 处理器,而且只有一种核心配置:面积为 315mm2 包含 12亿晶体管 (这已经接近GPU芯片的规模了)。 尽管采用了GF的32nm SOI工艺,推土机和现有的 45nm 6核心的Phenom II (346mm2)相比并不小多少。推土机芯片尺寸和晶体管数目大大的超过了intel采用32nm HKMG 工艺的 Sandy Bridge系列( 9.95亿晶体管, 216mm2.)。 这是个块头很大的芯片。

构架上,推土机和我们之前见到的CPU都很不一样。我们后面会更深入的介绍。FX芯片是由推土机模块构成的。每个模块有两个整数核心和一个共享的浮点核心。浮点单元占地较大,而且桌面级负载用到的的频率较少(服务器负载也一样),所以 AMD 让两个核共享一个浮点核心。AMD是按照整数核心个数来宣传推土机的。所以2模块=4整数核心(2浮点核心),4模块=8整数核心(4浮点核心),我们后面很快就会看从性能上这样做造成的结果。

【推土机架构】
自然的,我们从推土机模块的前端开始讲起。 指令提取(fetch)和解码(decode)部分是由一个模块里的两个整数核心共享的。这部分的作用是读取该线程的下一个指令,将X86指令解码成AMD内部格式,送到负责调度(scheduling)的硬件部分来执行。

解码硬件并不昂贵(应该指所占芯片面积),但是每个核新都来一份加起来就很可观了.尽管解码宽度(同时解码能力)对单个核心来说增加了,相对于以前的构架来说,推土机的多核结构实际上可能还有劣势 (Although decode width has increased for a single core, multi-core Bulldozer configurations can actually be at a disadvantage compared to previous AMD architectures. )让我们来看下面的列表来理解为什么有劣势。

对于单线程,推土机比前一代 (Phenom II)能提供更宽的前端。前端越宽就越强,这很好理解。但是看看我们增加核心数目的时候发生了什么。 由于指令读取和解码部分是由一个模块共享的,在同一的核心数目下,老的Phenom II结构反而提供了更高的解码速度上限。AMD这么做的很明显是基于这样的理由:系统只有在很少的情况下才受限于指令读取和解码的速度,所以共享这一部分是合理的。 AMD基本上是对的。很多指令要花几个周期来解码。在不同线程间切换能让指令提取和解码硬件更有效的被利用。只有在很特殊的突发情况下,前端才成为瓶颈
和intel的核心结构相比,AMD这方面是处于劣势的。
— 在Intel提供超线程的高端产品上,由于在每个周期,intel都可以读取两条线程中的任意一条的指令,AMD也没有任何优势可言。
— 同没有超线程的CPU 相比,AMD的优势也不明显。每个周期,Intel 的CPU能有更大的解码带宽,但是由于只有一个线程提供代码,总体解码器的利用率会比较低。
解码之后,AMD允许某些操作被当作一个操作捏在一起被下面的管线执行,这和Intel所谓的微代码融合技术是类似的( 首次在2003年出现在 Banias CPU 上)。 比较+分支,测试+分支,以及某些其他操作可以被推土机捏在一起执行—这有效的增加了后端执行部分的带宽。 这明显能增加IPC(每周期执行的指令数目)的技术在 Phenom II 上是不可能的。
【一个分离的分支预测器】
AMD 没有透露太多分支预测硬件的构造信息。但是我们还是能很快的发现一个很重要的改进:分支预测器(branch predicto)现在和处理器前端明显的分开了(decoupled)。

分支预测器的作用是预测分支指令的结果和跳转目标地址,而不是在分支结果出来之前白白等待。分支结果是根据以前的分支结果来的。拥有的数据越多,预测器就能更符合你的工作负载,预测的更准。准确的预测分支对于深管线的结构来说异常重要,因为一次错误的预测就会导致更多的指令被从管线里清空。推土机的管线深度比它的前一代有明显的增加,所以增强分支预测是必需的。
对于 Phenom II 和推土机,跳转分支都是在 管线的前端和指令读取在一起的。 对于 Phenom II, 读取指令有任何的卡壳(比如读取的指令不在缓存里)都会让整条管线停工,包括后面的分支预测。推土机 通过一个预测队列 让分支预测和指令读取分开了。 如果指令读取卡壳了,推土机的分支预测硬件还可以继续工作,做出下一步的分支预测,直到这个预测队列满了为止。
我们下面简单的说下该方案的有效性。
【调度和执行方面的改进】
和 Sandy Brindge一样,AMD 在推土机上 开始使用物理寄存器堆(physical register file = PRF) 的构架。数据只存在于一个地方(物理寄存器堆中)。执行引擎使用指针来跟踪 物理寄存器堆 中的数据。这个改动是为了节省能耗,因为在芯片中直接拷贝数据是很耗能的。

推土机中,给执行引擎提供数据的缓存和队列 都要比Phenom II 要大。更大的数据结构允许乱序执行的时候有更好的指令级并行性。 换句话说,推土机的发射端比前一代更强劲。但是不幸的是,虽然AMD在发射端前进了一步,但是在执行端就落后了。让我们先看看推土机好的一面:整数执行核心。
【整数执行核心】
每个推土机模块都有两个完全独立的整数核心,每个核心都有自己的整数调度模块,寄存器堆 和16KB 的L1数据缓存。整数调度模块每个都比Phenom II 的要大。

最大的变化是每个整数核心现在有两个端口而不是3个。单个整数核心包括了两个 AGU/ALU 端口, 而之前一代的设计是3个. AMD 声称在Phenom II里, 第三个 ALU/AGU 组基本山用不到,所以在推土机里被切掉了。
由于给整数核心提供数据的结构(前端?)更大了,AMD应该比上一代更容易的提高整数单元利用率。理论上AMD可以在 Phenom II 核心执行更多的整数操作,但是AMD说整个系统一般是受到其他部分的限制。
注:另说是四个端口 而不是两个 alu和agu并不是像Family 10h一样每对都挂在同一个rsv上面。
【共享的浮点核心】
每个推土机模块有一个共享的浮点核心给两个线程使用。如果只有一个线程有浮点操作,就会享受到全部的浮点硬件资源。否则两线程就要共享资源。

和一个4核的Phenom II相比, AMD 8核FX在浮点上没有缩水,AMD的整数和浮点调度总是分开独立的。Phenom II 和推土机有一样的执行端口数(应该特指浮点运算)。 和整数单元一样,推土机中的浮点核心有比Phenom II更大的调度模块。

问题是AMD的推土机必须包含更多的功能。 Phenom II缺乏 SSE4 和 AVX的支持,而推土机都支持。而且,AMD决定让他的浮点核心支持单步的乘-加指令(FMA)(注:就是一步内计算a+b×c,保持高精度)。支持FMA导致了浮点单元的相对面积的增加。所以虽然推土机浮点的吞吐能力没有比K8增加,但是能力提高了。 但是不幸的是,这也导致了x87/SSE2/3 浮点指令的峰值速度和前一代相比没有增加。 推土机的浮点只有在使用了 新的SSE(SSE4),AVX或者FMA指令的时候才更快,或者时钟频率比Phenom II有明显提高。
下面的 Cinebench 11.5 多线程负载 很能说明这种性能上的拖累。

和 3.3GHz 6-核 Phenom II相比,8核 推土机虽然有 9%的频率优势(考虑到turbo,差距更大),但是只有2%的性能优势。重度多线程的浮点负载下,推土机可能不比他们的6核前辈们好多少。
而且,推土机发布的时候,不仅仅要超过4核的前一代,还需要比6核 Phenom II做的更好。 比较浮点运算,Phenom II 有明显的优势:它可以比推土机执行多50%的 SSE2/3 和 x87浮点指令。
自从 Phenom II X6发布以来, AMD的主要优势就在于重度多线程负载—特别是得益于纯数量优势的浮点运算。推土机实际上在这点上有所退步,结果你就看到在同样的负载下推土机的表现和Phenom II X6持平或者更差。
和 Sandy Bridge相比,推土机只有2个优势:支持FMA 以及更高的 128-bit AVX 吞吐量。现在几乎没有用到FMA的代码,但是128-bit AVX 的优势是比较实在的。
【缓存层次构架和内存子系统】
每个整数核心都有自己独立的L1数据缓存。共享的浮点核心通过两个整数核心来读/写,和Phenom II 类似(尽管这里有两个整数核心)。推土机支持完全的乱序读/写操作,这点比Phenom II有改进,达到了intel构架类似的水平。L1 指令缓存和 L2缓存是整个模块共享的
指令缓存是 64KB,2路关联的大缓存,和Phenom II L1 指令缓存一样大,但是当然要和另外一个核共享。一个4核Phenom II 有总共256KB的 L1 指令缓存,但是4核的推土机就只有一半那么大。推土机的 L1 数据缓存也比上一代明显的少很多,Phenom II 有64KB的 L1 数据缓存,推土机每个整数核只有16KB。

但是推土机的 L2 缓存比Phenom II的要大很多。每个推土机模块有单独的2MB L2 缓存。 芯片上还有供所有模块共享的一个8MB大的 L3 缓存。 在第一波产品里,AMD不准备提供没有 L3 的桌面版本。但是AMD指出L3缓存只有在服务器负载下才明显有用。所以我们可以预期推土机的变种(Trinity?)会完全取消 L3。【事实上后来的Trinity和Richland等都没有L3】

由于缓存尺寸和核心高频率,推土机访问缓存需要更多的时钟周期。
注:另说不是因为要缓存尺寸和核心高频率 这个是为了L1的位宽 4周期的话 将来L1做到256bit也没问题
【追求高频率】
我们已经指出,推土机有好些资源从数量上比Phenom II结构要少了。大多数的妥协是为了增加功能的同时控制芯片尺寸(比如更宽的前端,更大的队列/数据构造,新指令集)。推土机从前端到执行部分,AMD改进性能都要依靠提高效率和频率(而不是数量)。推土机必须比Phenom II更好的使用资源,同时跑在更高的频率下,才能赶超上一代Phenom II。 所以推土机的一个重要目标就是要能上更高的频率。
AMD 的设计师把这称为“ low gate count per pipeline stage”(每一流水线阶段都保持尽量低的电路门数)。 通过减少每一阶段电路门的数量,可以减少在每一阶段花费的时间,从而增加处理器整体的频率。如果这挺起来很耳熟,是因为Intel用类似的方法来设计 Pentium 4。推土机不同的是,AMD坚持说他们没有像P4一样极端的追求频率,而是追求每阶段更少的电路门数目。 据AMD说,前者(P4)的功耗会导致问题而后者(推土机)在可处理范围内。
AMD对推土机的目标是比上一代 提高 30% 的频率。遗憾的是这是一个很含糊的说法,我也不能从AMD那里的到更明确的解释。 但是我们看看高端的Phenom II X6是 3.3 GHz,多30%就是说推土机要达到4.3GHz。可惜高端推土机没达到4.3GHz。发布时候最好的推土机是跑在3.6GHz,仅仅比前一代高了9%。 Turbo Core 能让推土机更接近这个目标,但是通常 Turbo Core 只能保持很短的时间。【FX9590不服】
也许你还记得在 P4 的日子,一个明显加长的管线会带来很严重的惩罚(前面说的预测失败带来的后果)。推土机之前,我们有两个增加管线长度的例子: Willamette 和 Prescott.
Willamette 比 P6 增加了1倍的管线长度【11级加长到20级】是由于补偿频率的提高。每个周期做的少了,当然要更多的是周期才能不影响性能。尽管 Willamette 的频率比即将退休的P6架构高,但是这个提高程度被工艺所限制。直到Northwood 的到来,Intel才能达到足够高的频率来拉开新旧构架的差距。
Prescott 更进一步加长了管线【31级】,幅度很大。但是让我们吃惊的是,Intel的设计师拿出了聪明的构架设计,在增加管线长度的同时,保证了每周期平均指令执行数目不变。这使得Prescott在达到高频率的同时也得到了高性能。Prescott 失败的是在功耗方面,高频率需要很高的电压,所以功耗顶破天了。
AMD 的目标是维持 IPC(每周期指令数)同时提升频率,和Prescott 类似。如果 IPC 保持不变,任何频率的增加就带来性能的提高。AMD试图通过更宽的前端,更大的数据结构,更宽的执行道路 来达到此目的。从很多方面来说是成功的,但是单线程能力和 Phenom II相比仍然有所下降。

从我们的Cinebench测试结果看:同频率下, 单核 Phenom II 几乎比推土机快7%。 这里已经包含了上面提到的有关IPC的改进。尽管AMD努力了,IPC还是下降了。
一点点的 IPC下降很容易通过提高频率来弥补,但是可惜AMD没能让频率达到推土机应该有的水平。
我们之前报道过 Global Foundries 32nm良品率的问题,我不能不猜测是不是和Llano同样的问题也在困扰着推土机。
【功率管理和真正的 Turbo Core 技术】
和Llano一样,推土机设计中对时钟和功率使用了大量的门控技术。功率门控允许某个单独的空闲核心几乎完全断电,为其他核心超过基础频率提供余量。 Intel把这种动态时钟速度调节称为 Turbo Boost。AMD 则叫做 Turbo Core。
Phenom II X6 使用的是一种未成熟的 ,没有功率门控的 Turbo Core 技术。 所以Turbo Core很少被激活 而且保持时间很短。
推土机的Turbo Core 就加强了非常多。它使用了Llano的数字估算方法来确定功耗(CPU知道某某操作要消耗多瓦的电)。得到的结果比我们在以前AMD高端芯片中看到的要更实在。

Turbo Core的细分度在推土机上没有改变:如果一半(或者更少)的核心是活动的,最大turbo是允许的。如果更多的核心在活动,就会选择一个更低的turbo频率。在基础频率上,只有这两种频率可用。
AMD现在还没有Turbo Core的监视程序,所以我们使用 Core Temp 来记录CPU在不同负载下的频率。从而测量 Turbo Core 对推土机的作用,同时和Phenom II X6 以及 Sandy Bridge 做比较。
我们先选取大量多线程的负载:X264 HD 测试。 每个测试包括 两个阶段,第一阶段是轻度线程化的视频分析,第二阶段是大量多线程的编码。我们输出前要运行4次,我测量的是Core 0(第一个核)的频率。
我们先来看Phenom II X6 1100T,它缺省跑在3.3GHz,少于半数活动核心的时候可以 跳到3.7GHz。如果Turbo Core正常工作,我们预期看到频率会在轻度线程化的第一阶段跳到3.7Hz。

可是测试中我们什么频率跳跃都没看见。Turbo Core 对Phenom II X6基本没起作用–至少是在这个负载下。平均频率是3.31GHz,刚刚在基本频率上一点点,很可能是由于华硕主板的原因。
那么我们来看看FX-8150 的 Turbo Core (最大4.2GHz,中间的是3.9GHz)

啊,有那么点意思了。虽然平均频率只是 3.69GHz (基础频率 +2.5% ),我们真正的看到了一些进步。这个负载对所有的处理器都是个麻烦,特别是下面给出的 2500K。

2500K 缺省跑在 3.3GHz 。但是 由于turbo, 测试中的平均频率是 3.41GHz。 我们看到有些尖峰跳到了3.5 和 3.6GHz. Intel 的 turbo 技术比AMD更平均一些,但是提高的平均量基本都在 3%.左右。
下面我们来看对turbo最有利的情况: 单线程程序。 一个单独的重负载线程,即使只持续一小会,也是turbo技术真正发光的场合。Turbo能帮助程序更快的启动,窗口更快的出现,在突发负载下更自如。
来看看我们的最爱,Cinebench 11.5。 它内建了一个非常棒的单线程测试。和上面一样,我们从Phenom II X6 1100T 起头:

Turbo Core 其实还是对 Phenom II X6 起作用的—就在非常短的时间片的内起了点作用。我们看到几个3.7GHz 的尖峰,但是其余部分 还是 3.3GHz. 平均频率还是 3.31GHz.
推土机就表现好多了

我们看到 4.2GHz 的尖峰有规律的持续出现,而持续稳定的频率维持在 3.9GHz, 正如你所预期的那样。平均频率是3.93GHz, 足足比 FX-8150.基础的3.6GHz 高了 9%

Intel 的 turbo 波动这次更频繁些, 在碰到TDP限制的情况下,在3.4GHz 和 3.6GHz之间跳跃 。 平均的频率是 3.5GHz, 比基础频率提高 6% 。AMD 第一次在Turbo 调频率的技术上比Intel做的好了。虽然我还期望看到更平滑的turbo 选项,不可否认 Turbo Core是推土机一项真正的的特性,而不是我们在Phenom II X6上看到的残次品。下面是Turbo Core对我的一些测试中能带来的提高:

所有测试平均性能提高大约为5%。不是那么震撼性的数字,但是是这仅仅是个开始,别忘了Intel刚开始 采用turbo技术时也不怎么样 ( Don’t forget how unassuming the first implementations of Turbo Boost were on Intel architectures. ) 我真心希望在以后的推土机改进版上看到更显著的 Turbo Core技术。
【独立的时钟频率】
在AMD介绍原始的Phenom 处理器的时候,AMD许诺会由于每个核新独立的频率而更节能。你可以Core 0 跑在2.6GHz, 而 Core 3 在1.6GHz 跑个轻负载。 实际运用上,我们感觉Phenom的异步时钟其实是个负担,因为CPU和OS的调度的联合作用,有时候花很长时间才能把频率提升到需要的速度。这个结果至少在当时导致了有核心来回切换的负载会有显著的性能损失。这个问题实在太严重,最后AMD放弃了在 Phenom II 使用异步频率调节。
这个特性在推土机中又回来了。这一次AMD相信 不会出问题了。 第一个重大改变是Win7,核心挂起( core parking) 能够防止某些线程在可用核心间无规则的切换。第二是因为推土机提升/降低频率的速度远远快过原始Phenom芯片。 也可以把这个归功于 Turbo Core 这个主要特性带来的福利。
推土机异步的时钟频率在我们的测试中还没有带来任何问题。但是我也不能鲁莽的说这是个优点,至少在我们对这个特性有更多的实际经验之前不行。
【推土机(深)管线带来的影响】
一个新的分支预测构架,和一个未知的,但是大概更深的流水管线? 我很想知道AMD为了提升推土机频率背了多大的包袱。我启用了值得信赖的N-皇后测试(已经被AIDA64集成了)。
N-皇后问题很简单, 就是在NxN棋盘上如何放N个皇后让它们互相攻击不到。求解这个问题是及其分支密集型的,所是一个对深管线影响度很好的测试。
AIDA64 带的 N-皇后求解器算法是重度多线程的。但是我想先看看单核心的表现。所以我屏蔽了推土机其他的核心,只留一个。 同时我也比较了稳定频率和 Turbo频率下的速度:

遗憾的是结果不那么美妙。 即使打开了 turbo, 3.6GHz 的推土机还要再提高 25% 才能赶上同频的 Phenom II X4. 甚至 3.3GHz 的 Phenom II X6 也比推土机做的更好。由于不知道AIDA64做了什么优化,我就多不关注Intel的结果了,,但是Intel关注分支预测的性能是广为人知的。
如果我们对N-皇后测试开启所有的核心,上面性能上的问题随着线程数增多就轻易被掩盖了。

但是很明显的是,对于需要频繁分支的单线程或者轻微多线程操作,推土机会拼的很艰难( be in for a fight.)
【Windows 7 应用程序的性能】
测试平台

【3dsmax 9】
如今桌面处理器已经快到足够在自己家里实现专业的3D渲染了。为了看看(推土机)在3dsmax 下的表现,我们采用 在 3dsmax 9 SP1 里的 SPECapc 3dsmax 8 测试 (只包含CPU渲染测试)。 一下结果是渲染综合成绩(数字越高越好)

作为我们第一个重度多线程,浮点为主的工作负载,我们看到 FX-8150 露出了他的牙齿。相对于Phenom II X6有明显提升 。FX-8150 紧紧的咬住了Core i5 2400,但是还不能和 2500K 以及 2600K相比。
【Cinebench R10 & 11.5】
Cinebench 由 Cinema 4D的人制作,是一个很流行的3D渲染测试,可以提供单线程和多线程下3D渲染的结果。

如我在前面提到的,推土机的单线程性能还是有些令人失望的。这张图算开始揭示这个现实。 即使 FX-8150包含了Turbo Core增加的频率, 它还是比 Phenom II X6 1100T慢。 Intel 的 Core i5 2500K 在单线程上比FX-8150要快50%。

增加线程数,FX-8150 开始发光了。 最后和基本同价位的 2500K不相上下。

即使采用了更新型的负载(Cinebench 11.5)。FX-8150 在单线程上还是不行,上图中 2500K 比它快了 44% 。

采用新型的多线程负载,推土机就表现的很不错了。但是比老的 Phenom II X6 1100T 多出优势 比我们希望看到的要少。
【7-Zip 测试】

重度多线程显然比较对推土机的胃口,这里的 7-zip 测试中,FX-8150 甚至比最快的Sandy Bridge(2600K)还快。
【PAR2 】
测试Par2 是一个用来修复下载文档的程序. 它从给定文档中产生奇偶校验数据,以后可以用来恢复文档。
Chuchusoft 采用 par2cmdline 0.4 的源文件,使用 Intel Threading Building Blocks 2.1 将其多线程化。得到的 par2cmdline 能分出多个线程来恢复 par2 文档。测试中我们使用了一个 708MB 的文档。损坏了其中的60MB,然后使用多线程的 par2cmdline 来恢复它,数字成绩是恢复所耗时间(s)

(上图是多线程成绩,数字越小越好)当采用多线程的时候, FX-8150 再一次超过了 Core i5 2500K。
【TrueCrypt 测试】
TrueCrypt 是个非常流行的加密程序包,它支持完整的AES-NI 指令 。它还内置了测试CPU性能的测试包:

推土机增加了AES-NI 加速,这个特性在Phenom II X6 是不存在的。所以 FX-8150在 AES 加密/解密速度方面是顶级之一。 只比 2600K 慢点。 Intel 认为的以超线程来给CPU分档看出了效果,2500K明显的比8线程的2600K慢.
【x264 HD 3.03 测试】
Graysky 的 x264 HD 测试使用 x264 编码来压缩 4Mbps,720p的 MPEG-2 源视频。这个程序强调质量而不是速度,所以该测试程序分两步来压缩,最后给出在每步内的平均帧数

我前面说过,我们的x264 HD 测试第一步是轻微线程化的负载.所以 FX-8150 表现的不怎么好。即使是老的 Phenom II 也能比它快一线 。 Sandy Bridge 则明显做的很好。【实际上1pass只是初步的处理】

第二步采用了更多的线程,让 FX-8150 有展示它肌肉的机会,第一次和2600K打平。【2pass才是关键,提升画质减小体积,耗时更长】
AMD还发给我们一些重新编译过,支持AVX 和AMD XOP指令的 x264 测试可执行文件。我们两者都做了实验,让我们看看打开 AVX 的性能怎么样。

(轻度线程化,支持AVX,数字越大越好)
所有的处理器都跑的更快了,但是Intel仍然在这个轻度线程化的测试中保持了明显的优势。

(重度多线程化,支持AVX,数字越大越好)
在第二步,排名改变不太大。帧数都有普遍提高。FX-8150 在X86 转码方面非常强,和Intel 的 Core i7 2600K 基本持平。虽然在这里没有给 AMD XOP 成绩,但是它和 AVX 的结果是一样的。
【Adobe Photoshop CS4】
为了测试 Photoshop CS4 性能,我们采用 润色速度测试 (Retouch Artist’s Speed Test)。 这个测试做一些基本的图片编辑;有一些色彩空间转换,创建很多涂层,色彩曲线调节,图像和画布尺寸调节,unsharp mask,最后全图做高斯模糊。
整个过程用时被记录下来,由于我们使用了 Intel X25-M SSD 作为我们的测试盘,性能读书比我们用机械盘要稳定的多。时间结果是(秒)数字越小越好,测试是多线程化的,可以利用4核处理器的所有4个核心

推土机的 Photoshop性能比 Phenom II X6 有了明显的进步,但是可惜还是赶不上 Sandy Bridge .
【编译Chromium 测试】
你们以前要求测试下软件编译性能,这次我终于找到了一个好例子:用Visual Studio 2008 编译 (谷歌的)Chromium(就是Chome浏览器)。这是个很大的工程,双核处理器要跑40分钟。但是结果是可重复的,而且可以轻松的跑满8线程以上。所以对我很合适。

我们的编译器测试传统上更倾向于多线程的构架,但是我们这里发现Phenom II X6 1100T 比推土机 明显的要快一截。虽然AMD的(新)处理器都还有竞争力,这里作为一个例子,能看出AMD新构架的折中设计没有得到回报—至少没有更高的频率是不行的
【Excel 蒙特卡洛 测试】

在我们这个最后一个应用程序测试中,推土机又一次击败了 i5 2500K. Intel的超线程也是个大赢家,8线程的2600K is 轻易的超越的推土机. 怎么说,这里AMD 推土机用更少的钱给出了更多的性能。
【游戏性能测试】
AMD 明确的在(推土机)测试者指南中说,受CPU限制的游戏性能不是FX构架的强项【所以有了Mantle,目前mantle已死,但它的的衣钵已经被vulkan和DX12接过】,这应该是因为其比较差的单线程性能。但是看看在 受CPU限制 或者 受GPU限制 的两种情况下的表现,能有助于我们更精确的描绘出CPU是怎么处理游戏负载的,也包括在现在最新游戏中它的表现。
【Civilization V】
文明5 的后期游戏测试给出了两个结果。平均渲染帧数 和 只针对CPU的非渲染帧数

虽然在整个渲染过程中GPU是瓶颈,但是AMD平台似乎有少许的优势。我们在以前也见过这种结果:在GPU瓶颈的测试中,一种平台比另一种表现好,这实在难以解释。但是在同一家族中,更快的CPU没有优势,GPU限制了一切。

无渲染测试的结果,CPU的排名和我们预期的一样。 幸好FX-8150 还比他的前辈要快点,但是还是落后于Sandy Bridge。
【Crysis: Warhead】

在 Crysis Warhead 的CPU瓶颈环境中, the FX-8150 比 Phenom II 还慢。 Sandy Bridge 继续保持大幅领先。
【Dawn of War II】

我们在 Dawn of War II 看到类似的结果。轻度多线程就不是AMD’s FX 的强项,更早的 Phenom II X6 也跑到了它的前面。
【DiRT 3 】
我们跑了两个 DiRT 3 测试,以分别得到 受CPU限制和 受GPU限制的 结果。第一个是受CPU限制的设置:

FX-8150 这里表现的不好,还是落后于 Phenom II。但是在更符合现实的 受GPU限制设置中,推土机表现的还可以:

【Dragon Age】

另一款 受CPU限制的游戏 , FX-8150 又一次落后了。
【Metro 2033】
Metro 2033 即使在低分辨率下也是 要求很高的,但是更倾向于 GPU 的瓶颈。FX-8150 和 2500K 持平:


【Rage vt_benchmark 测试】
虽然ID 的Rage 没有很好的测试手段,我们仍然可以有测试该游戏一个独特的方面: Megatexture。Megatexture 动态的从磁盘读读取纹理数据,然后组成该引擎使用的贴图。这是一个重要的部件,能让ID 开发者给这个游戏世界赋予独特的纹理。但是由于大量的使用了独特的纹理( ID宣传原始的数据超过1TB), ID 需要有创造力的压缩游戏材质到游戏允许的大约20GB大小。
Rage不是以GPU能直接使用的纹理格式(比如DXTC/S3TC)来存储的 ,而是以压缩率更高的 (JPEG XR)格式—S3TC格式做多做到6:1的压缩. 所以你每次读取材质的时候,Rage需要将其实时转化为 S3TC格式。这种转码在游戏中一直都在进行,而且对CPU是个明显的负担。
vt_benchmark 测试 先清空纹理缓存,然后记录转换当前场景需要的纹理要多少时间,线程数可以从1 到X。所以在跑这个测试的是偶,它可以测试1-8线程的结果(缺省数值是CPU决定的)。这显然是个纯CPU测试。下面的成绩用到了各CPU允许的最多同步线程数。

FX-8150 表现的很不错,但是 Phenom II X6 1100T 也一样很好。两者都比Intel 2500K快,但是比 2600K 还差些。如果你要看性能随线程数的变化。下面的图表就是了:

【星际争霸2】
传统上在Intel平台上表现的很好,推土机没有给我们带来惊喜。A黑游戏

【World of Warcraft】

(注:魔兽世界一般被认为是最多利用到2个核心的CPU游戏,所以是轻度多线程的)【所以也是一个A黑游戏】
功耗测试:跨平台比较功耗是不那么容易,因为主板的功耗差别很大。 就看看AMD家族, FX-8150增加的功率和时钟门控,在推土机的待机功耗上得到了回报,比 Phenom II 们好很多。 Sandy Bridge 仍然看起来更凉快些。

但是在系统负载下,推土机就很费电,轻易的就超过了同频 Phenom II X6

我怀疑 GF 的32nm 工艺水平 +推土机的高频率是问题所在【不用怀疑了这就是事实】
超频:AMD指出,要超频,FX-8150 可以用风冷达到4.6GHz 左右,水冷达到 5GHz ,更高的频率需要更极端的冷却方法。 在我们的实验中,采用盒装散热达到4.6GHz 毫无问题。超出这个频率就会严重的降低稳定性。我在4.7GHz 都不能启动和测试,几乎总会遇到死机。 我用风冷达不到 5GHz 。

【结论】
大多数情况下 AMD FX-8150 可以拉近 Phenom II X6 和 Intel Core i5 2500K 之间的差距。如果负载合适,推土机甚至可以和顶级 Sandy Bridge 较劲。我们终于有了一款采用功率门控,和工作正常的Turbo Core特性的高端AMD CPU。遗憾的是AMD这些年来一直受到抱怨的单线程性能(lightly threaded ),仍然没有改进,推土机在这方面很蹩脚(Bulldozer simply does not perform)。更糟的是,在一些重度多线程的引用中,推土机相对上一代 Phenom II X6 的提高太小,现有AM3+平台的用户不值得为此升级。AMD发布的推土机虽然总体上比上一代更有竞争力,但是不是在各个方面都有改善。AMD 非让你在 单线程性能和多线程性能之间做选择。在这个功耗选通和Turbo Core 被采用的时代,我们根本不应该被迫做这种选择。
推土机当然是一个有意思的构架。但是我觉得它还没有准备好。 很明显AMD需要更高的频率来让推土机真正的发光,但是不管由于什么原因,AMD没做到这一点。当打桩机明年出现的时候要提高提高10%-15%的性能,看来AMD打算大大改进现在的构架缺陷。我唯一不确定的是:核心上15%的提高是否足够赶上已有的差距。和 2500K 相比, 后者对推土机有40-50% 的优势。我希望推土机以后的改进版能有更给力的Turbo Core频率,这对于拉近差距很有用。

AMD还和我们说,Win7 对推土机优化还不够好。由于AMD独特的模块化结构,操作系统线程的调度需要知道什么时候要把线程归到一个模块,什么时候要分到有独立缓存的不同模块。Win 7 的调度没考虑到推土机的结构,看到哪里有空就塞到哪里。而没有考虑最优方案。 Windows 8 预期会解决这个问题。但是由于推土机评测的准备时间很短,我们还没有足够的Win8平台下的测试。 这也是由于Win8 在明年底的时候才会推出,而到时候推土机很可能已经有升级版了。

那么如果现在你要花钱,会买什么? 如果你已经有了一个高端Phenom II 系统,特别是X4 970 以上或者X6,我认为你没有任何理由再升级。如果你要坚持你的平台,那么你最好等到下一波AM3+产品线的到来。如果你要买新的,那么我觉得2500K总体来说是是更好的选择。你会得到更可靠的性能,不随应用不同而变化很大。而且你还得到 Quick Sync 之类的特性。在许多方面,推土机在AMD一贯做的好的方面明显有优势:重度多线程的程序。如果你主要是跑线程化很好的负载,那么推土机一般会带来超过Intel 2500K 的性能。

我本来希望推土机能弥补AMD以往的弱点,而不是只增强它拿手的方面。我觉得这个构架会在服务器领域表现不错,但是在客户机方面AMD还没有提供有足够有竞争力的产品。推土机缺乏单线程性能的真正的原因很难 追查,简单的回答可以是时钟频率问题。我们已经听说了最近 Global Foundries 遇到的麻烦,推土机也许就是最新的受害者。 如果AMD对推土机频率的目标是比Phenom II增加30%。那么AMD在 FX-8150就没做到。我听说以后的推土机变种会强调IPC的增强,而不是强调频率。但是如果非要说是哪一个因素限制了推土机的成功,我会说是频率。第二个因素是因为AMD要在32nm技术下控制芯片面积。现在推土机是非常不“苗条”的。我觉得随着AMD向更小的晶体管转移,会弥补一部分推土机物理(尺寸)上的不足。
好的消息是AMD 有很给力的路线图【虽然现在证实执行的很好,即使有部分夸大,但是停止桌面FX系列更新有些遗憾】,我们希望它能被很好的执行。我们都需要AMD雄起。我们已经看到,如果没有AMD的强力竞争会怎么样:我们会得到人为受限的CPU,超频极度受限,特别是在比较便宜的档次。我们毫无选择因为没有替代产品。我不认为推土机是个足够强的替代产品能让Intel回到极度竞争状态。但是我们的确需要推土机达到这种水平。我相信AMD能做到,但是仍然需要很大的进步才行。 AMD 不能只靠他的 更好的 GPU构架来卖APU,它需要提高X86的性能–更明确的是说,AMD需要在单线程性能上做提高。推土机没做到这一点,我担心打桩机也还不够。但是如果AMD能保持每年一更的步调,而且很好的执行,还是有希望的。 AMD回到Athlon 64的年代,这不是一个会不会的问题,它必须这样! 否则我们就和选择权说拜拜了【近几年AMD的低迷和Intel的孤独求败正是推土机架构失败的结果】
Part1【推土机评测】结束,部分翻译来自CHH,注释是我加的,接下来的的几个部分均为自翻




part2 呢
@blabla:连接…