本次文章将由三篇组成,其实是上个月的Intel Accelerated,之前的Intel Architcture Day 2021,个人渠道收集来的信息以及rumor的整合,基本全面覆盖制程,封装,架构,CPU和GPU的各个方面。
这篇文章相当于part0,上个月Intel Accelerated的大部分内容,结合个人的一些看法,不属于IAD2021的内容,但是又不能不讲。这篇文章里不会提到具体密度数字。因为毫无意义,更不会进行什么四则运算云密度。
制程 (改名)
Intel Acclerated 2021活动上Intel公布了“新的“工艺以及封装路线图,其中争议比较多的大概就是制程改名看齐foundry这件事。
制程改名及抹杀可以说是Intel的优良传统之一(?),只是前几次改的都没有这么夸张捏。
之前改过两次,第一次是把所有工艺去掉一个加号,Icelake的10nm+改成了10nm,10++改成10+,10+++改成10++,直接抹去Cannonlake及原版10nm(10nm-),原因显而易见。

所以2019年Icelake-U发布前后,Intel的各方面描述里就没有了“10nm+”这个字眼。往后的所有材料里Ice Lake,Lakefield以及Jasper Lake等的工艺都换成10nm代称。这次改名后的名字我从来没有用过,太过混淆,不如直接用原来的名称。
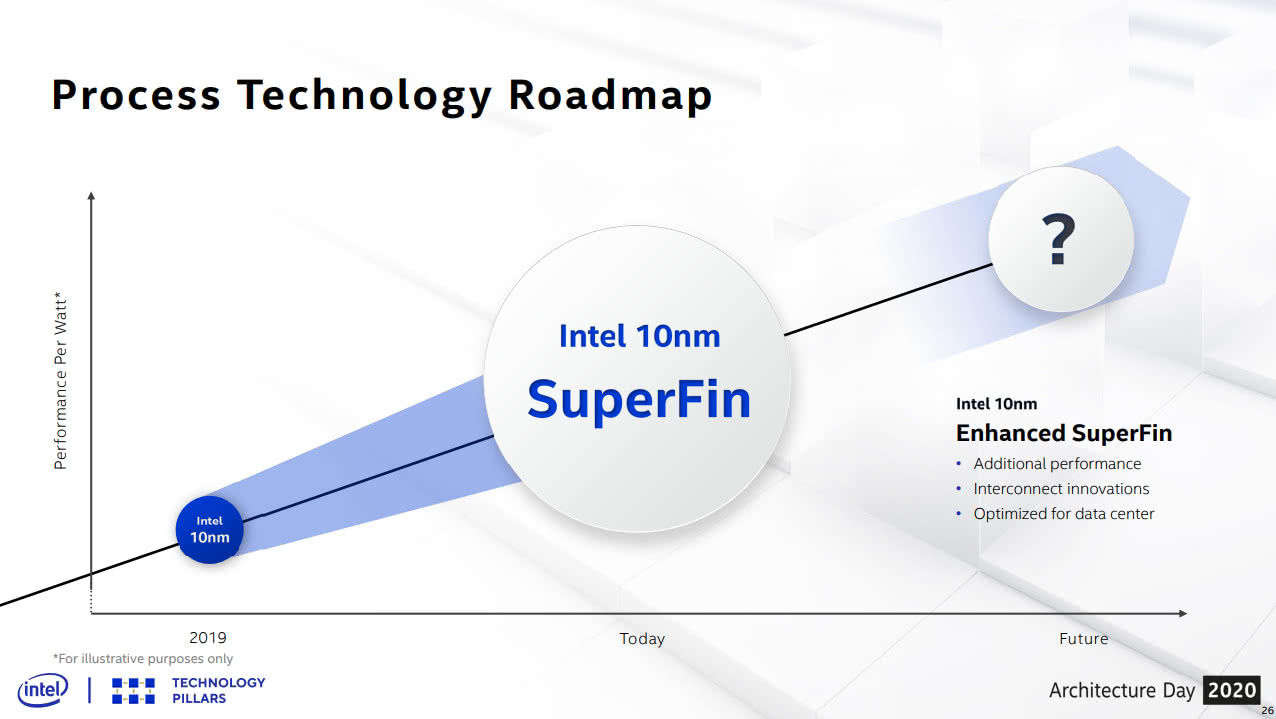
第二次改名是Tiger Lake-U发布前后,可能因为14nm++++的加号多到难以分清,Intel决定放弃加号命名,使用更加容易分辨的独立名称,Tiger的10nm++再次改名为10nm SuperFin(10SF),Alder的10nm+++改名为10nm Enhanced SuperFin(10ESF)。
第三次冲击改名就是这次了,也是改变最大的一次。Intel完全抛弃了原有的纳米数,向密度相近的foundry制程(TSMC/Samsung)看齐,也因此拿掉了制程名中的纳米数。

就结果而言,Intel命名向foundry看齐我觉得是一件好事。本来现在命名和feature size早已无关(pitch scaling早就死了)。Marketing上没有了劣势。以往每次比较制程都需要把Intel制程转换一下再来比较,还要科普为什么不能拿Intel 7nm和foundry 7比,为什么Intel 10nm密度和N7相当这种事情。当然,Intel 7nm够不够格改名Intel 4,7+够不够格叫I3这些事情就等工艺实际出来再说。另外2nm命名为20A这个操作有点迷惑,命名不够统一…..
P.S. 根据个人从某些员工那里收集到的信息,Intel的原计划就是把+、++这些制程,从14nm时代的PDK更新带来的个位数提升,变成往里塞进更多工艺改进,
导致后来的+的含金量(懂不懂什么叫含金量啊)比14nm时代的要高,用加号来表示接近1个foundry node的性能提升不太合适(但是密度应该是不会有太大变化的)。说了半天,Intel其实是在学习foundry,逐渐把加号转变成half node,把以往的大跃进分割成更小的步子。
Intel 7/I7 (原10ESF/10+++)

Intel工艺改名,从这里开始。
原名10nmESF/10nm+++的它,现在叫做Intel 7。原本只是又一个加号的它,带来的能效提升却不小:相较10SF,能效提升了10-15%。
改进的地方有晶体管通道应变性提高,降低contact阻抗,更多的金属层数以及供电方面的改进等。详细如下表。
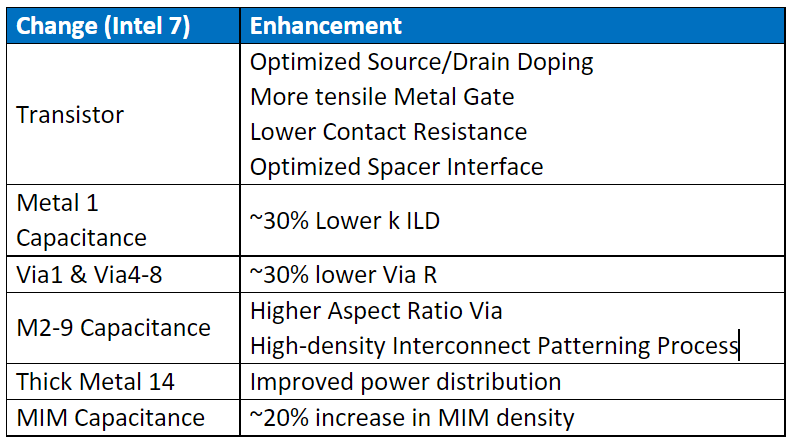
BEOL方面,通过导入low-k LID降低了M1层30%的电容。M2-M9层的Via高宽比变得更高,互联图案化工艺密度更高,导致电容减少。

特别是密度更高这一点我不知道详细到底是啥,考虑到10nm的BEOL已经用到了SAQP (Self-aligned quadruple patterning, 自对准四重图案化,主要给M0及后面几层提供更高密度)和SADP(double),再密就只能EUV了….但是官方并没有提到10+++/I7有用到任何EUV,所以还是全套DUV制程。此外Via1及Via4-8的阻抗也降低了30%。
M14金属层改善了供电及布线,主要是为需求更高服务器处理器所准备的(Sapphire Rapids,功耗爆炸)。MIM电容容量增加了20%。
Intel 称I7的密度和foundry 7nm相近,甚至可能高于部分foundry 7(有猪!我不说是谁)。

Intel 7 将于今年Q4首发于Alder Lake处理器,此外明年Q1 PRD,预计Q2发布的服务器处理器Sapphire Rapids也将使用Intel 7工艺。
Intel 4/I4 (原7nm)

Intel 4/I4,原Intel 7nm,是Intel的首个EUV制程。相较Intel 7(10ESF),它将带来20%的能效提升。
这个Intel 4与最初的Intel 7nm已经不太一样。最初的Intel 7nm 计划时间比较早,所以并没有完全使用EUV,工艺过于复杂。这次的Intel 4经过重新设计,完全利用了EUV(”fully embrace“),简化了工艺流程。
Intel 总计使用了12层EUV。


Intel 4 预计于22H2 PRD,HVM及出货在2023。首个产品将会是消费级的Meteor Lake处理器的compute tile,然后是Granite Rapids的compute tile。关于这些产品我们会在Part1和Part2讲到。
MTL已于Q2 tape-in,虽然这个时间点并没有什么实际意义。
同样,根据个人目前从消息源得到的信息,Intel 4 将会是一个”完全为了密度“的制程。甚至可能已经用上了更加复杂的双重曝光EUV(目前N5还是单次曝光)。I4工艺的产品也将会利用到这密度,具体产品线和核心数我已经得到非常明确的数字。反之频率可能不会做到I7那么高。 虽然Kelleher博士所称I4目前晶体管性能和DD (defect density)进度正常,但目前来看之前进度最早的几款I4产品都还是MIA状态(PVC compute tile已经上了N5)。MTL/GNR的schedule还在变化。根据个人得到的一些信息,I4工艺之前遇到了一些问题,具体原因我也知道(当然无法公开),只能说问题不是很大,全看流片结果了。
Intel 3/I3 (原7nm+)

Intel 3,原7nm+/++,将提供18%的能效提升。
I3主要改进在新的HP standard library 标准高性能单元库,对于Intel 这喜欢搞HP cell spam的来讲着实用得上,但除此之外的密度改进并没有提到。其他改进还有BEOL的金属层互联优化,更多EUV层数,更高的驱动电流等。
Intel 3预计于2023H2 PRD,HVM定在2024。
Intel 20A/I20A (原5nm)

Intel 20A/I20A,原5nm,是Intel继I4之后下一个大的节点。单位换成了A (Anstrom),意为埃,1nm=10A。


I20A 主要有两大革新:全新的GAA晶体管结构,Intel 叫RibbonFET,以及PowerVia,将BEOL中的供电与信号分离。
RibbonFET
RibbonFET是Intel的一种GAAFET晶体管,GAAFET是什么就不再赘述。下面先来简单介绍为什么要用GAA。
Pitch scaling早就已经没了,这个不谈,the horse is already dead。它不是目前制程最关键的地方,现在都做的是track scaling。
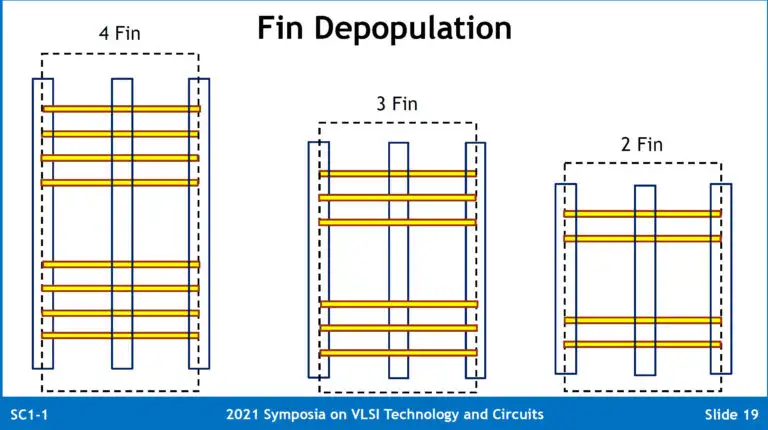

现有FinFET晶体管基本靠通过fin depopulation等手法进一步做下去track scaling。为了延续track scaling所做的fin depolulation,会将Fin削的更薄,更高(drive current),安排的更密集,这样依然会导致驱动电流降低。
为了进一步降低cell height,需要新的晶体管结构,也就是现在的GAAFET。GAAFET有好几种implementation,包括Nanosheet,Forksheet,CFET(complementary FET)等。Nanosheet跟FinFET一样,都是单独的device,而Forksheet和CFET将把nMOS和pMOS结合,进一步降低cell height。
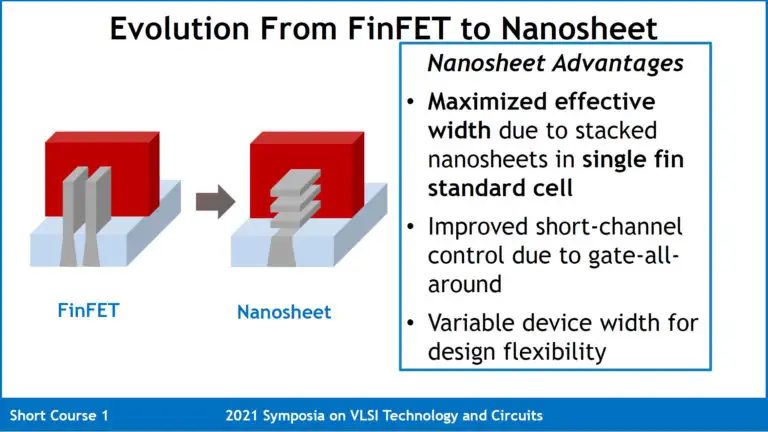
显然,工艺当然要一步步来,Intel的RibbonFET就是类似Nanosheet形式的晶体管结构。foundry也会有类似的工艺,比如Samsung采用MBCFET的3GAE/3GAP,以及台积电的N2。

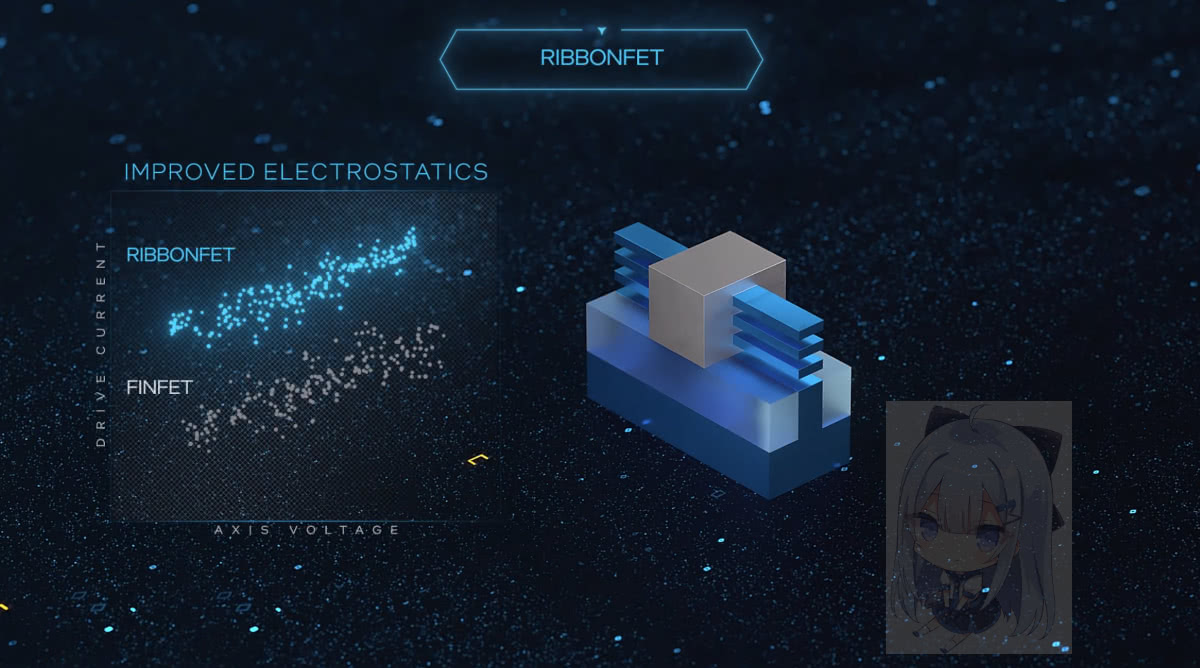
与FinFET不同,水平Nanosheet/RibbonFET的sheet是垂直叠在一起的,并通过调整它们的宽度来达到所需求的性能指标。这样就没有了FinFET那种需要性能就要堆更多Fin,由于Fin pitch是固定的,增加的Fin反过来会增加track height那样明显的弊端。
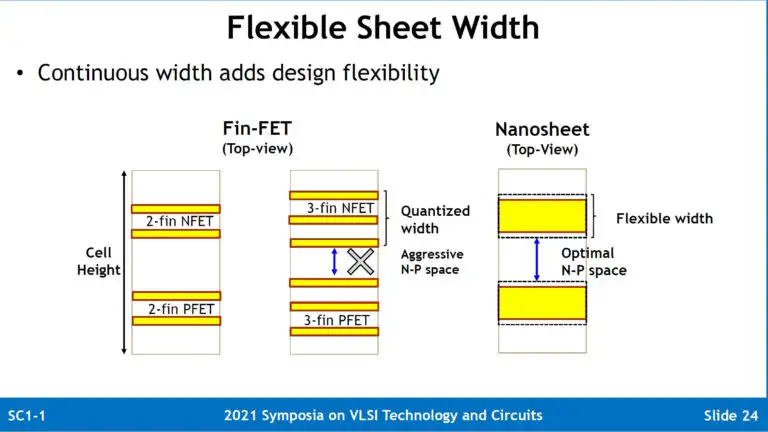
增加密度,突破FinFET track scaling限制的同时,Nanosheet/RibbonFET还能提高驱动电流。


Intel 展示了了4层堆叠的RibbonFET及其测试晶圆。
PowerVia

除了RibbonFET,I20A还引入了另一个革新:PowerVia。


在传统的制造工艺里,通常将晶体管称作FEOL(Front-End of Line),后端互联及金属层称作BEOL(Back-End of Line)。BEOL要同时承担供电和传输信号两个任务。



而PowerVia相当于把这两种线路分离开,上面放信号,背面放供电线路,然后把晶体管夹在中间。


这样下层的供电线路就可以通过TSV直接进行链接,不需要和信号线放在一起。同时信号线也不需要跟供电线路共享BEOL,能够达成更高的密度,或者更快的速度。
PowerVia的供电线路,是需要在另一块独立晶圆上做好,再与有晶体管的逻辑电路晶圆进行结合(wafer bonding)。
这种将供电线路放在背面的工艺,三家foundry里目前Intel是第一个公开宣布在做的。

采用RibbonFET和PowerVia技术的I20A工艺预计于2024H1进入生产。
Intel 18A/I18A (原5nm+)

Intel18A/I18A,是I20A的后继工艺,仍将使用RibbonFET结构。
归功于Intel和ASML的紧密合作,Intel会于I18A节点引入业界首先的全新high-NA EUV光刻。high-NA (0.55NA) EUV的光刻精度比现有0.33NA EUV系统更高,业界将使用0.55NA 单次曝光替代0.33NA 双重曝光,良率及性能均会有大幅提升。
I18A预计于2025年早些时候投产。Intel认为I18A能为其带来工艺上的领先地位。
2025+

2025年及以后的事情,就有点太早了。目前的可能性有:stacked GAA,也就是前面所说的CFET,将nMOS和pMOS完全堆叠在一起,而不是像nanosheet那样独立开来。
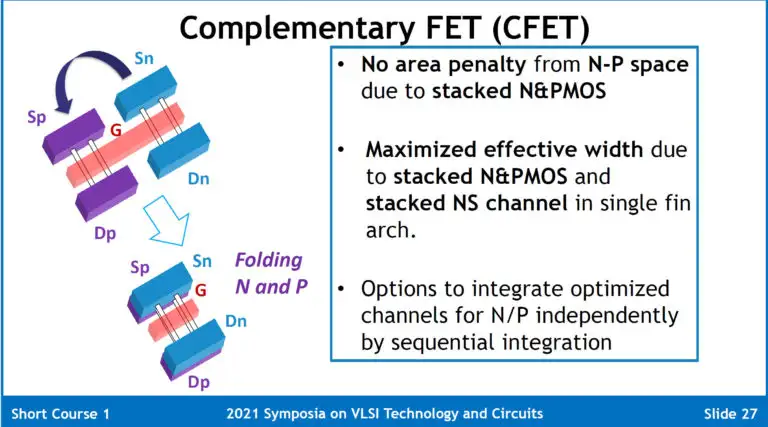
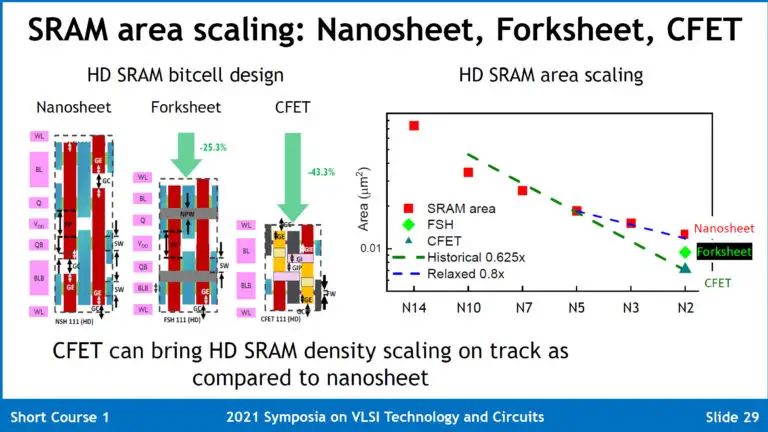
CFET能够大幅度降低cell height,达成比nanosheet高得多的SRAM密度。
另外Intel 也提到了下一代PowerVia和先进的光电子封装。
Intel Foundry Services (IFS)
额哼,我Intel Custom Foundry (ICF)又回来啦!(大雾
10nm灾难,一击击沉LG连芯片都没做出来的SoC业务,其他代工5G芯片的客户也蒙受巨大损失,这就是战功显赫的ICF。
现如今,IDM2.0战略下ICF改名IFS,准备再次进入芯片代工市场。
这次公开的客户不多,只有两个:高通和亚马逊AWS。


高通看上了IFS的I20A制程,应该是想代工高性能移动SoC。
亚马逊不准备用制程,而是看上了Intel的先进封装技术,可能会见到TSMC制造,Intel封装的Graviton服务器CPU?
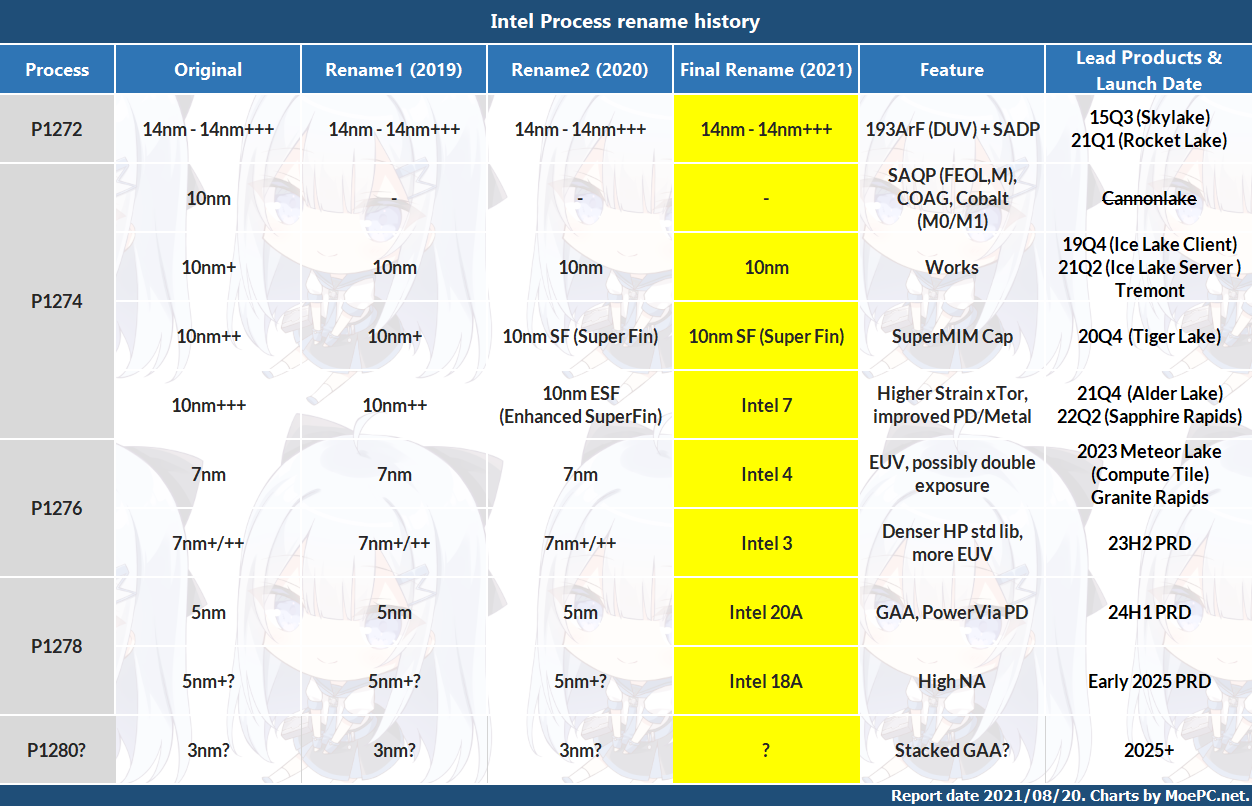
总表
总结Intel更名及制程特性的总表如下,最右为领衔产品及大致的PRD/launch日期。
封装
除了bleeding edge制程,Intel也带来了先进封装技术的路线图更新。
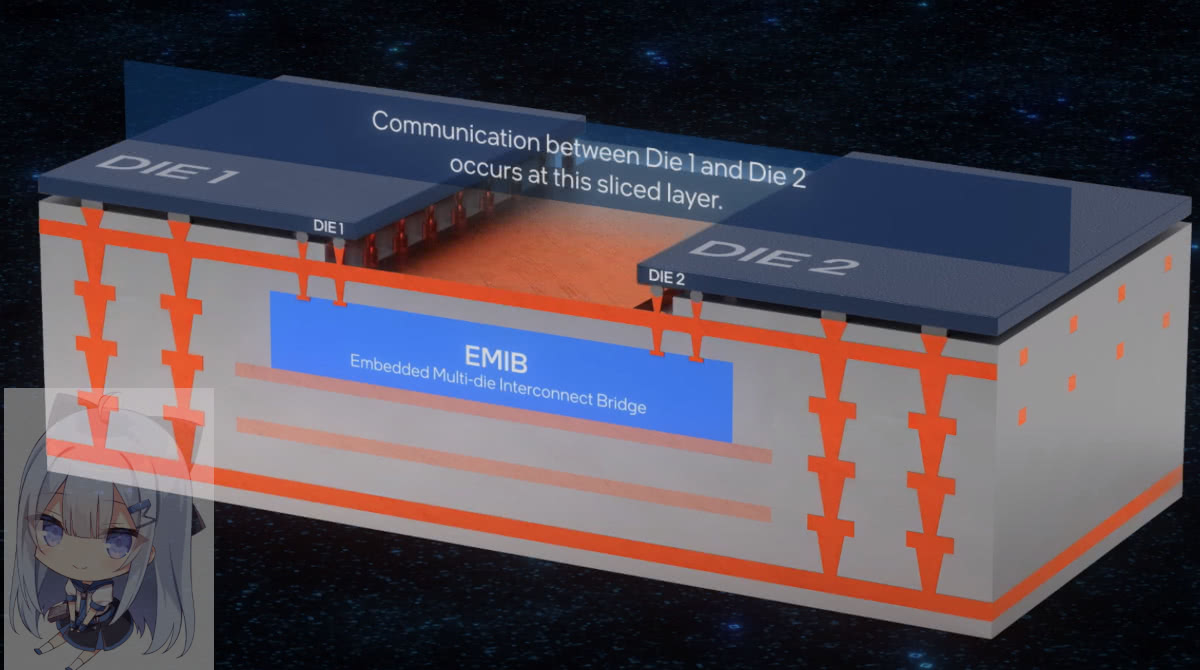
EMIB (Embedded Multi-die Interconnect Bridge)
EMIB这东西,大家应该早就有听说,毕竟吹了很久,也是挺不错的技术。
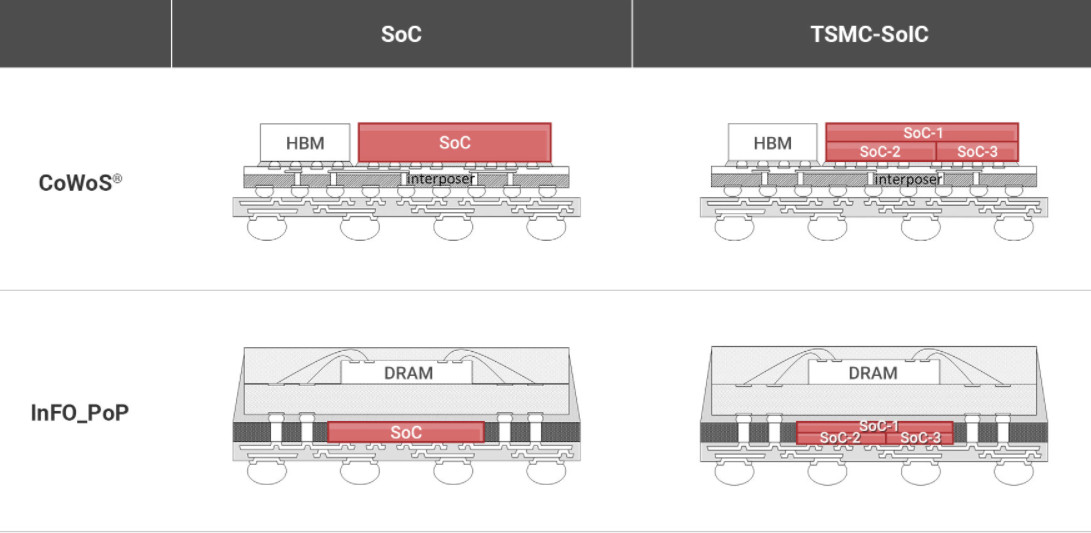
目前的封装技术主要分为3种,台积电的CoWoS(Chip-on-Wafer-on-Substrate)那种使用interposer的2.5D技术,属于投产最早,应用最广泛。Interposer其实也可以看做一块芯片(passive 和active interposer) ,相当于芯片和基板之间的中介,和芯片直接采用μbump连接,比普通的organic package的IO密度要高得多。

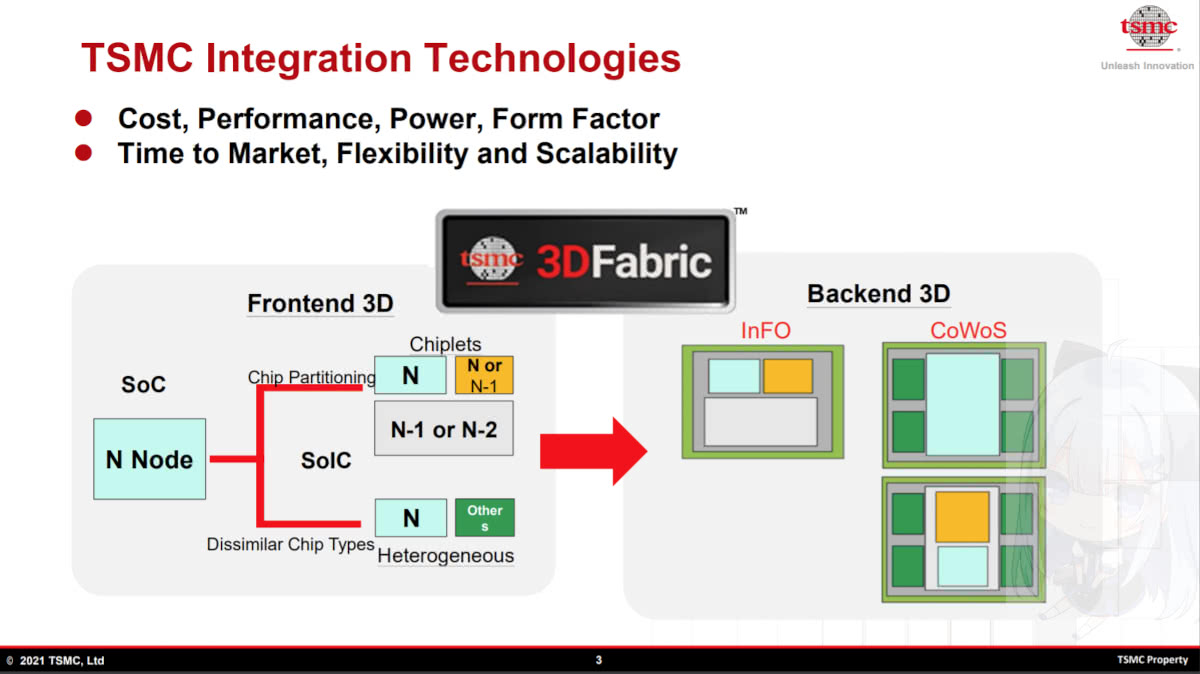
CoWoS-S(STAR),最常见于GPU+HBM的2.5D封装类型,bump pitch大概在150μm左右。
早前的CoWoS-S受到光罩(reticle)大小限制,现在TSMC已经将CoWoS-S的面积上限提到最高3倍光罩。
关于台积电的先进工艺和封装技术,以后有时间了会写两篇文章,这里就不多说。

而不使用一整块interposer,只在局部采用一个小型的bridge die的这种2.5D技术就是EMIB,以及TSMC的LSI(Local Si Interconnect)技术。EMIB成本更低,也不会受光罩大小限制。




大致原理如图,我觉得很清楚了,不废话。


3D封装则是后面会讲的Foveros和TSMC InFO/3DIC。
EMIB早在2017年的Kaby Lake-G上就有应用,Intel用它连接KBL-G的Polaris22 GPU和HBM显存。

目前使用的EMIB都是第一代,μbump pitch为55μm。
2017年的Kaby Lake-G也好,2022年的Sapphire Rapids也好,都是55μm的EMIB。
Intel 这次说明了未来两代EMIB的更新:第二代EMIB的μbump pitch将缩减至45μm,第三代EMIB进一步缩小至40μm。具体schedule未知。


Intel 还声称,将会使用第二代EMIB 制造一块封装大小为92x92mm的服务器处理器,是世界最大的BGA封装。(具体给哪块用的我觉得大致都能猜到吧….)
Foveros
Foveros (1st gen)
Foveros是Intel 自家3D堆叠封装的名字,类似于TSMC的3DIC。使用Foveros的首款产品Lakefield,一同发表于2018年的Intel Architecture Day。
但实际产品实际上2020年才登场(i5-L16G7/i3-L13G4)。
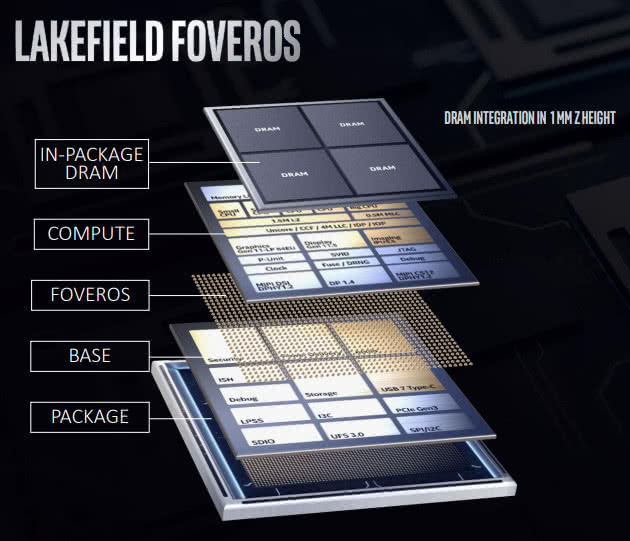
Lakefield所使用的第一代Foveros,将一块高功耗的10nm compute die 通过μbump 堆叠在低功耗的22FFL base die上。
compute die内放了1x Sunny Cove + 4x Tremont 核心,缓存,以及一块64EU的gen11核显。
22FFL base die则类似芯片组,放不需要特别高性能及功耗的组件。实际上这个base die更像一块active interposer。

第一代Foveros 的bump pitch 为50μm。
Foveros Omni (2nd gen)
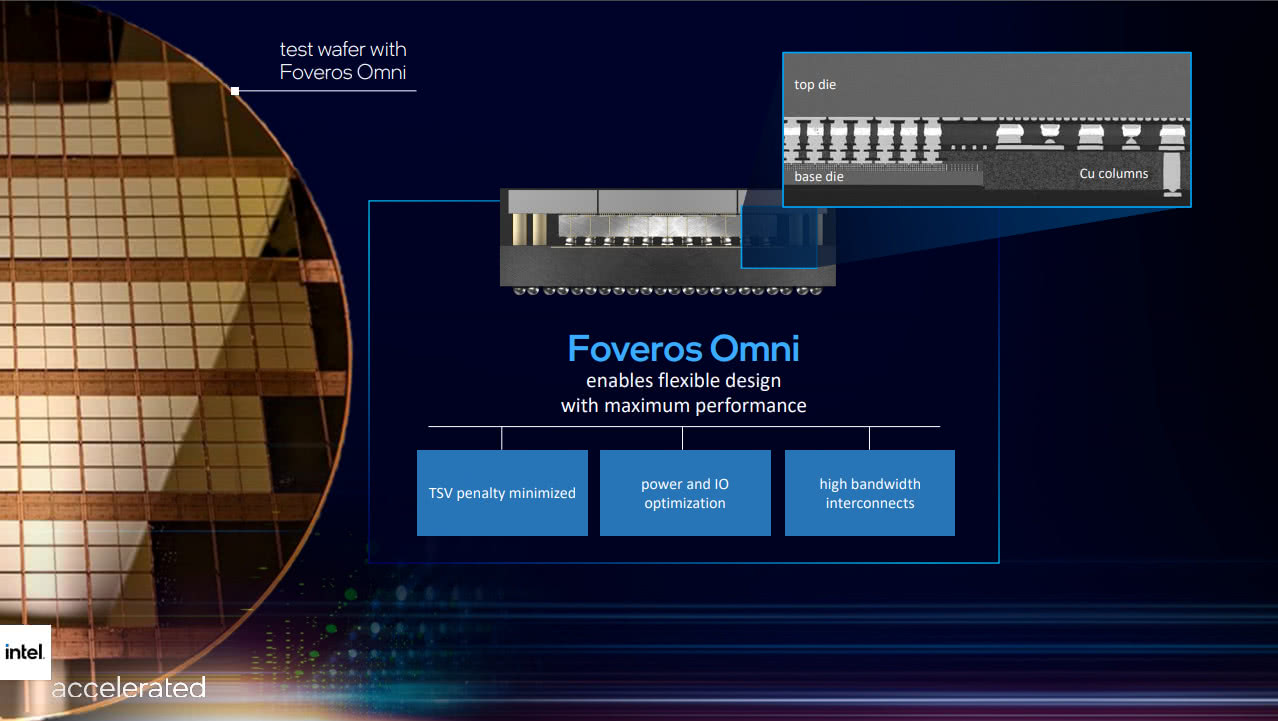
第二代Foveros,Intel称之为Foveros Omni,将是下一代Intel 服务器/消费级产品线的核心技术。

主要改善点在于将供电线路从TSV挪出来,变成外部的“copper columns”,也就是把供电和信号线路分离,使得die与die之间的信号线路TSV可以做到更高密度,同时保证信号不受干扰。这个技术之前叫ODI(Omni-Directional Interconnect)。

同时,Foveros Omni的供电和IO方面也有优化,互联带宽更高。Foveros Omni还支持多块base die的配置。

Roadmap上虽然写着Foveros Omni将bump pitch 缩小至~25μm,但首款Foveros Omni的产品——Meteor Lake 则只有36μm的bump pitch。(个人猜测可能MTL没有做ODI?
MTL将支持5-125W的TDP范围,堆叠了Compute die,SoC-LP die以及GPU die。

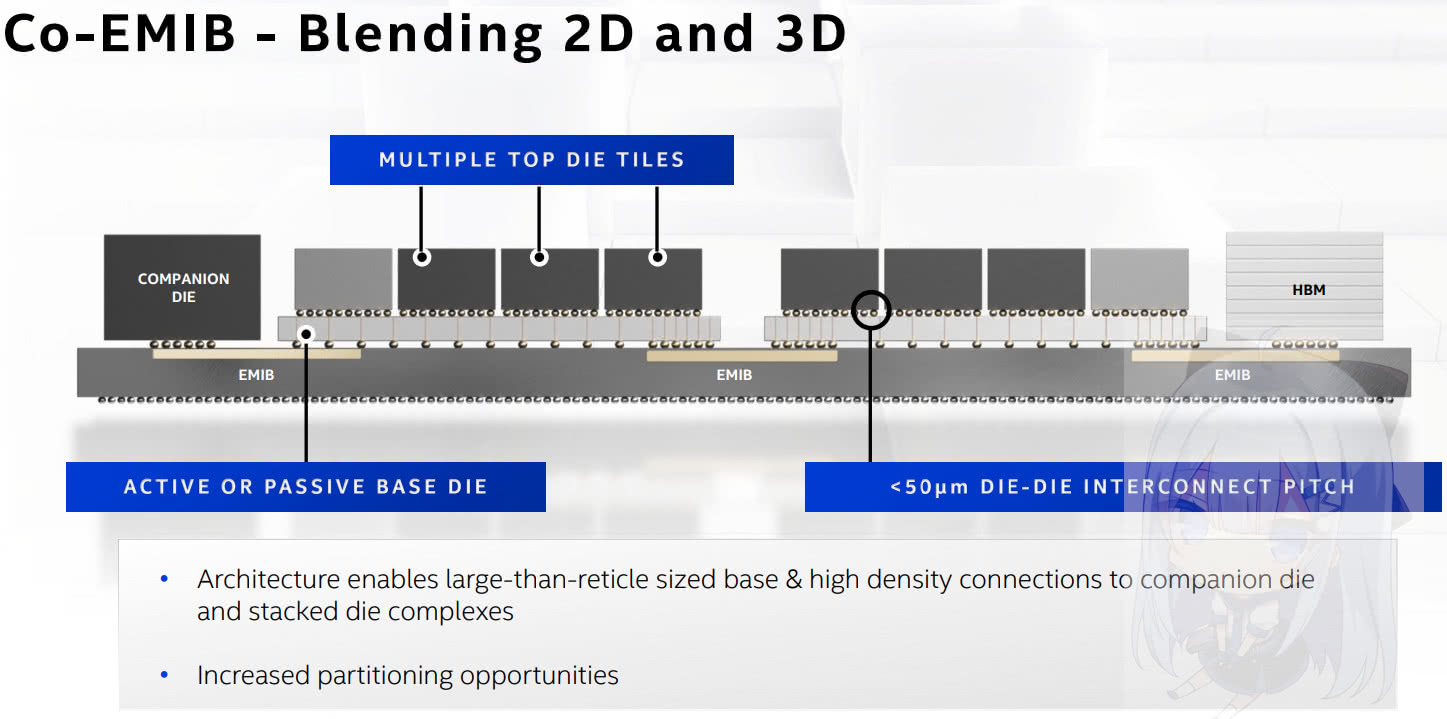
除了Meteor Lake,Intel 的大家伙Ponte Vecchio也用了Foveros Omni。PVC的技术叫做Co-EMIB,将EMIB和Foveros Omni并用, 做到了极高的复杂度(一共塞了47块die)。
Foveros Omni 预计于2023H2 出货给合作伙伴。
Foveros Direct(3rd gen, Hybrid Bonding)
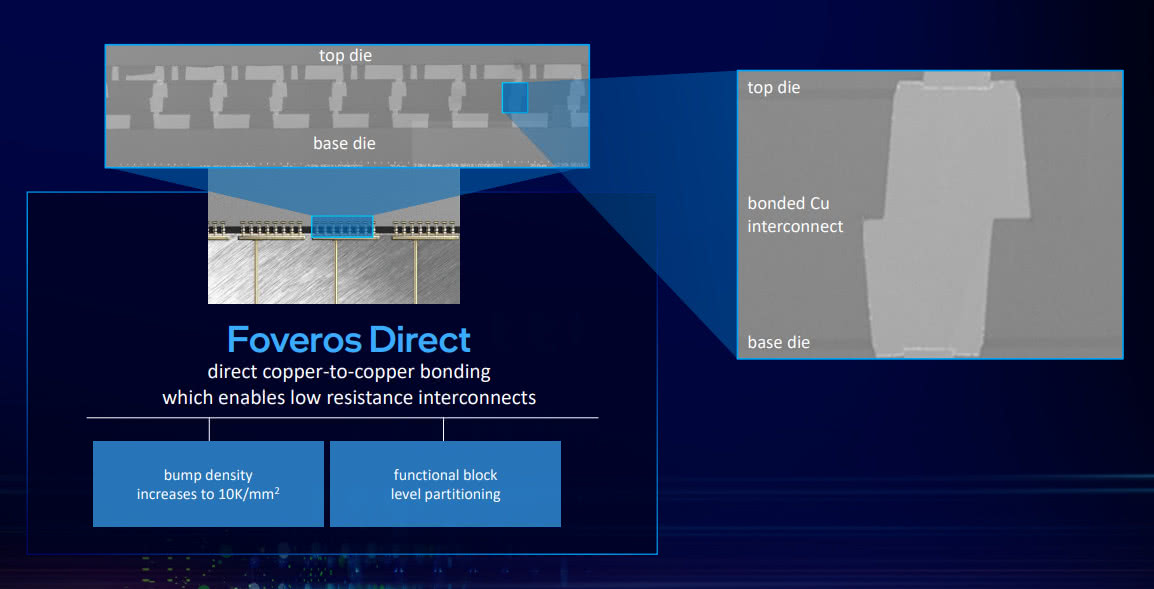
第三代Foveros 叫做Foveros Direct,属于hybrid bonding技术。die 与 die直接使用铜互联,阻抗更低,密度相比上面的Foveros Omni大幅提升。

Foveros Direct 的bump pitch 约为10μm,每mm2可以做到10000+个bump。
顺便一提,AMD今年的3DV$所使用的3DIC已经是类似技术。通过hybrid bonding把bump pitch做到了9μm。
上面所提到的Foveros以及第二代Foveros所用的都是Solder bonding。其实相当于使用铜质电极触点,顶上有焊接材料,通过reflow加热回流焊实现上下die的连接,然后在空隙里填充上underfill材料。
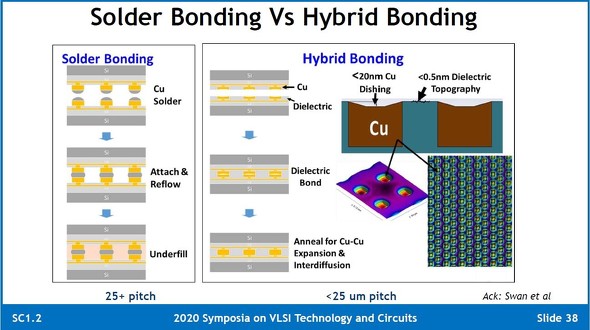
与Foveros Gen1/Foveros Omni所使用的solder bonding 触点结构不同,hybrid bonding 是下面用铜电极做出一个凹陷(凹陷低于20nm),表面形成一层绝缘材料(dieletric),磨平至厚度低于0.5nm,然后进行直接结合。结合后加热铜电极受热膨胀两边就会接触上了。
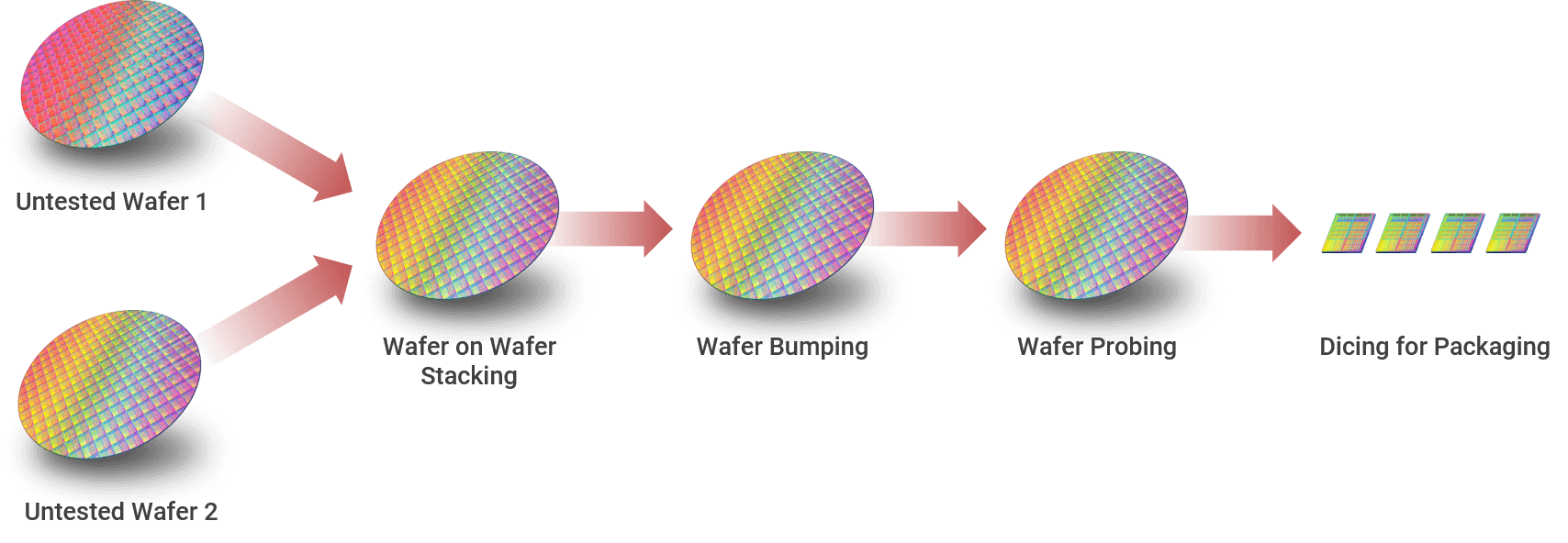
hybrid bonding适用于5-25μm的μbump,die to wafer的结合(SOIC中称作CoW,Chip on Wafer)。
微缩至1-5μm的μbump,则需要wafer to wafer的hybrid bonding,TSMC称作WoW(Wafer on Wafer)。
Foveros Direct 和Foveros Omni 一样,预定出货给合作伙伴的时间都是2023H2。




沙发, 路线图什么的编出来不就是为了推翻的么(大雾
其实还是比较期待新款atom,不知道会不会出八核的sku,基站的那个最高24核sku其实拿来做边缘/家庭服务器很合适啊,可惜没见到零售,早些时候还有xeon d系列来着。
xeon-d现在都拿来做smartnic了哈哈