Update 210630: 更新了Sapphire Rapids泄露的Linpack性能及功耗,可以文章末尾找到。
如果你见过roadmap大概会料到吃枣会有这么一天。终于捂不住了。
还记得2018年Intel的data-centric innovation summit么?当时有这么一个roadmap。

当时Cascade Lake还没出货,Cooper Lake-SP计划2019年,Ice Lake-SP计划2020年发布。两者共用Whitley平台。
这里的这个Cooper Lake-SP代号为CPX-4,为2-die MCM封装,共48C。具体的其实和Cascade Lake-AP差不多,只是CLX-AP是BGA+高TDP的水冷平台(250W那几个倒可以风冷所以有人用),而这个Cooper Lake-SP则是48核心的主流Whitley平台,LGA4189。
后面就都知道了。Cooper Lake-SP没了。Cedar Island平台的Cooper Lake-P因为Facebook等要用所以仍然存活,用于2S(Sonora Pass)和4S/8S(Angels Landing),在高端的4S/8S服务器算是接替Cascade Lake-SP。

但是主流的2S服务器依然要用Whitley平台,Ice Lake-SP 原定2020年Q4左右(额,这是第几次跳票后的“原定”日期我都不太记得了)发布,但由于10nm等各方面的问题,General Availability(GA)发布还是跳票到今年的4月。
现在ICL发布了,Milan和它之间的巨大性能差距我们今天不谈,可以去看Anandtech最新的那篇测试,Milan有压倒性优势。
Cooper被砍,Ice Lake跳票也导致Whitley平台很长时间没有U可以用。(所以这个空窗期很多都投奔EPYC了)

2019年investor meeting的ppt。当时20H1”预定出货“,当时还在sampling…

从上面的几张roadmap都可以看到原定的2020发布。(4-5Q cadence,xswl)
Ice Lake的延期同时也导致Sapphire Rapids的schedule顺着往后推。Sapphire Rapids之前定档2021Q4左右(我手上的官方roadmap,而且是最早的segment),这就导致原计划的Ice Lake发布到Sapphire Rapids发布之间只差了2Q左右。
当然如果你看到过schedule的情况肯定会知道SPR不可能Q4。而且就算按照原定schedule最重要的部分还是会比较晚。
跟之前10nm和7nm的情况一样,roadmap在跳票之前看起来“太过美好”,直到官方不得不承认的那一天。
另外插一句,Intel 7nm(特指Meteor Lake)目前遇到了一些问题,具体原因我有问到。详细的暂时不透露。
背景铺垫废话说完,开始正题。Intel 今天官方宣布Sapphire Rapids 跳票到2022Q2。实际投产2022Q1,production ramp在2022Q2(MASS VOLUME Q3?)。相当于往后跳了至少两个季度。但是这两个季度相当关键,后面会说。
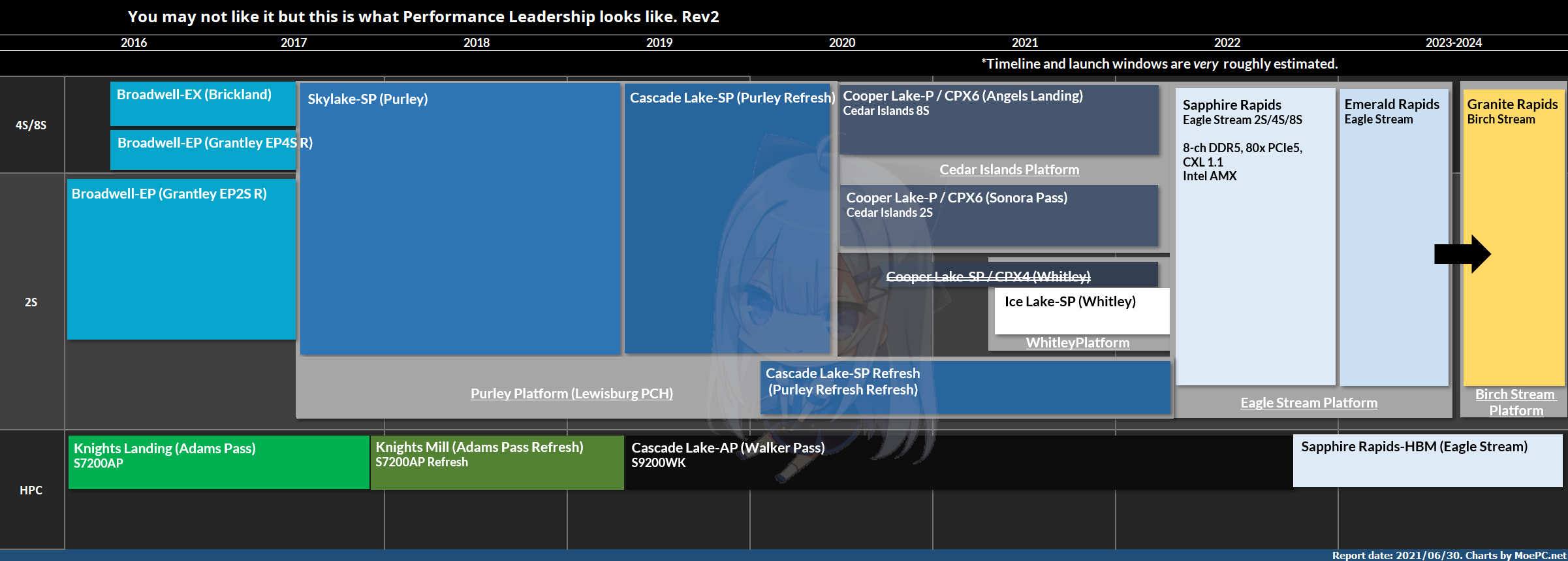
上图是更新后的服务器roadmap。删掉了很多不太适合公开的规格细节。
Sapphire Rapids是Intel 重拾服务器市场竞争力相当重要的第一步,采用Intel 10ESF工艺制造,4-die EMIB MCM封装,最高56C/112T(设计60C)Golden Cove架构,采用8通道DDR5 4800,80条PCIe 5.0,CXL 1.1互联。里面还塞了一大坨DSA等其他单元。
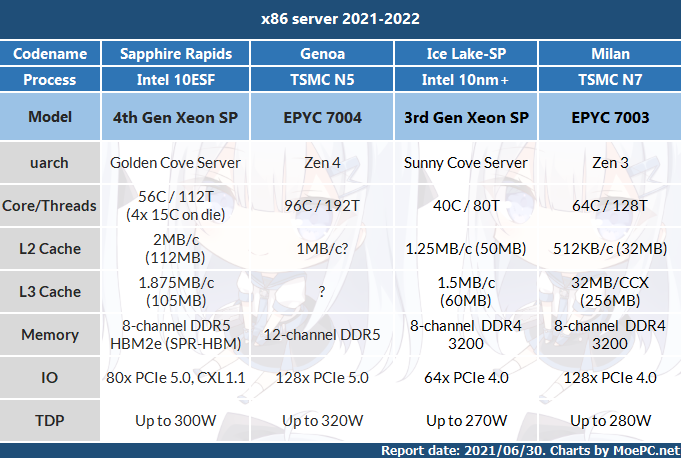
缓存结构上GLC server的L2为2MB,L3为1.875MB/c(credit:Skyjuice)。
56核心的话总共有112MB的L2,105MB的L3,加起来一共217MB,已经相当可观。
Intel 原本的算盘是让它和Milan 64C竞争。Golden Cove 是个很肥的架构,虽然perf/w很难看,但相比Zen 3 是有IPC和性能优势的(单颗核心面积爆炸换来的),能和Milan打的有来有回,拉高功耗的话甚至能够全面压制Milan。(此时功耗高于300W)。再加上DDR5和PCIe5,以及DCPMM等特性优势,如果真的能够按照原定计划2021年内发布,会非常有竞争力,而且Milan的供应非常紧张,Intel自己的fab供应不会受TSMC限制,能够在Genoa发布前的空窗期抢占相当的市场份额。
但是这一延期到2022Q2 会导致SPR的位置比较难堪。因为到2022年下半年AMD的EPYC 7004,代号Genoa就会发布。
Genoa将会采用Zen 4架构,TSMC N5工艺,IPC大幅提升(具体多少不能说)。目前已知的Genoa 最大配置为96C/192T,相对Milan直接增加50%,同时搭配12通道DDR5 5200,理论带宽为Milan 8通道DDR4 3200的244%(普通Milan,无3DV$)。PCIe也升级到128条5.0。所以Genoa在核心数,内存带宽以及IO上均有压倒性优势。
当然特殊的HBM2e版本Sapphire Rapids 搭配AVX512跑浮点还是会非常强的,毕竟带宽摆在那里。不过SPR-HBM会比通常版本的SPR还要晚,而且它主要面向HPC,和一般的server版本SPR/Genoa不是一个市场。
如果是服务器和DC市场,Genoa将会提供更强的性能,更多的核心,面对ARM的服务器也会更有竞争力,SPR将会面临各方面的劣势。接下来AWS的Graviton 3,Ampere的128核心 Altra Max(wwwwdo you like L3?),以及高通收购NUVIA后的采用Phoenix架构的Orion服务器都会是很强的对手(Graviton3跟Altra Max其实不太算….尤其Altra Max)。ARM的N2架构的PPA也是很出色的,V1个人看数据觉得其实一般…..扯远了。
想必Intel到时只好利用自身平台优势来给顾客下菜了。惯用的有Optane SSD和DCPMM之类,以及AMX,DSA和CXL等功能上的支持。但归根到底实际核心的性能以及能效还是会有很大差距。后面的Emerald Rapids也仅仅只能小小的提升一下,并不能根本解决问题。Granite Rapids就更别说了…我们距离它还很远。纸面上GNR的规格和性能都不错,跟SPR一样,问题是Intel 已经没有那么多时间和机会了。
更新:VCZ泄露了Sapphire Rapids水冷版本的Linpack性能和功耗

这是水冷版本的SPR,base 2.7GHz,双路共52核心。Linpack单节点功耗800W。
保守估计8通道DDR5 4800 单node 100W(电压比DDR4要低),所以双路实际功耗600W左右,和roadmap相符(实际SPR有高于300W的SKU)。
单路26核功耗达到300W,Linpack单路2.9TF,运行频率大概在3.49GHz。这还只有26核就已经达到300W。top bin核心能达到两倍以上的56C会怎样呢?(虽然HPC不太会用top bin,基本都用单路1x-2x核的SKU)
满规格SPR最高TDP数字大家可以先自己想象一下(我有TDP range)。保证跟PVC OAM的600W TDP一样,是个让大家大开眼界的数字。
所以在此我建议,Intel 在销售SPR的时候,随U附赠灭火器比较合适。
顺便计算了一下 Icelake-SP水冷,Cascade Lake-SP,Skylake-SP,Milan和Rome的理论性能。图中附有actual的则为来自Atos的实测数据。
SPR依靠AVX-512跑HPC还是挺不错的,只是Genoa来了就………
PR完整原文:
Lisa Spelman
Corporate Vice President, General Manager of the Xeon and Memory GroupBy Lisa Spelman
It’s been a few months since we launched our 3rd Gen Intel® Xeon® Scalable processors and I thought it was a good time to share an update on our next-generation Xeon Scalable processor,code-named “Sapphire Rapids,” which we are hard at work on. We’ve talked at a high level about what’s coming in this platform, and today I want to highlight two of the breakthrough technologies featured in Sapphire Rapids and provide an update on timing.
Sapphire Rapids will feature a new microarchitecture designed to address the dynamic and increasingly demanding workloads in future data centers across compute, networking and storage. The processor is supported by a rich set of platform enhancements that will drive the adoption of industry-changing technologies like DDR5 memory and PCIe 5.0.
Sapphire Rapids is built to be Intel’s highest performance data center processor, delivering low-latency, high-memory bandwidth across workloads. As we announced this week at the International Supercomputing Conference, versions of Sapphire Rapids will be offered with integrated High Bandwidth Memory (HBM), providing a dramatic performance improvement for memory bandwidth-sensitive applications.
I’m excited to share more information about two new advanced acceleration engines that we’re building into Sapphire Rapids.
I’ve talked extensively about the leadership position we have in the area of artificial intelligence (AI) within Xeon, and as AI workloads continue to grow in importance across all our customers, we are doubling down on our leadership position with Sapphire Rapids through the integration of Intel Advanced Matrix Extensions (AMX). AMX is our next-generation built-in DL Boost advancement for deep learning performance and features a set of matrix multiplication instructions that will significantly advance DL inference and training. I’ve seen this technology firsthand in our labs and I can’t wait to get it in our customers’ hands. I don’t want to give away everything now, but I can tell you that on early silicon we are easily achieving over two times the deep learning inference and training performance compared with our current Xeon Scalable generation.
The other major acceleration engine we’re building into Sapphire Rapids is the Intel® Data Streaming Accelerator (Intel® DSA). It was developed hands-on with our partners and customers who are constantly looking for ways to free up processor cores to achieve higher overall performance. DSA is a high-performance engine targeted for optimizing streaming data movement and transformation operations common in high-performance storage, networking and data processing-intensive applications. We’re actively working to build an ecosystem around this new feature so customers can easily take advantage of its value.
Demand for Sapphire Rapids continues to grow as customers learn more about the benefits of the platform. Given the breadth of enhancements in Sapphire Rapids, we are incorporating additional validation time prior to the production release, which will streamline the deployment process for our customers and partners. Based on this, we now expect Sapphire Rapids to be in production in the first quarter of 2022, with ramp beginning in the second quarter of 2022.
Sapphire Rapids is an exciting release for us and for the industry. The advancements in performance, workload acceleration, memory bandwidth and infrastructure management will lead the industry’s transition to cloud-based architectures and help shape the data centers of the future. We look forward to sharing more technical information on our next-gen data center platform in the coming months, including during Hot Chips 2021 in August and Intel Innovation in October.
Lisa Spelman is corporate vice president and general manager of the Xeon and Memory Group at Intel Corporation.
via: Intel Pressrelease,VCZ, atos



之前Meteor Lake不是tapein了么,感觉7纳米还行?
生产力就是一切的基础
本质来说还是10nm生产线的问题
之后是怎么样还要看7nm生产线能否比较顺利
10nm还是能耗比太辣鸡了,英特尔的设计也很垃圾
两个火炉相乘效果
低频的话确实
然而现在的拖延 推迟问题 本质还是在还以前10nm欠下的债罢了
现在10nm应该算是真的完成了 其实速度还是算快的了 但产品打磨时间不够长 如果让产品立马出来 应该会非常难看
如果10nm早就完工 ICL早就应该出来了 正因为10nm一步慢 所以步步慢
要说看以后能不能有竞争力 那还得看7nm以及封装技术那些的顺利程度 还跟10nm一样那落后时间再加3-5年
只要生产力在线了 早做产品早打磨也可以早发布 就有竞争力
SPR延迟应该是意料之中 看看超算那边就早就知道了 如果不延迟并且成品很好的话 那就是开挂了
如果ADL也加入延迟大军 我也不会意外
ICL早就出来了 感觉是pcie4.0的锅吧
7纳米不知道什么样子的 之前那次公开推迟股价直接血崩
应该说是SP跳票 反正当时外界很多人觉得10nm已死没有再玩下去的必要 证明良率一直不行 并且这工艺的疗效也一般
但拖了那么久现在总算是出了一个勉强还能用的
10nm最早都要追溯到17年还是18年那会? 忘了 要是那时候就完工了 也不用继续玩老架构马甲
反正还是那句老话 一步慢步步慢 10nm早完成 有更多时间打磨 产品也更早出来 而不是延期半年甚至一年多
也不用出啥火箭糊这种backport辣鸡玩意
想一想要是连Golden Cove都用14nm的境况 哈哈哈 我是想象不出来
对于7nm甚至5nm 我觉得如果今年IEDM不讲更多内容 证明真的又卡住了