首先是昨天WWDC大会上发布的iMac Pro将搭载的Radeon Pro Vega,下面是Vega架构的新信息

产品页介绍有两款
1款是Radeon Pro Vega 56,搭配8GB HBM2
更高端的为Radeon Pro Vega 64,搭配16GB HBM2
看到这里就多少有些明白了…这次是用CU数量来命名,不错的方法,简单易记
那么Radeon Pro Vega 56就会有3584SP
Radeon Pro Vega 64则采用完整Vega10,4096SP。

关于性能数字,苹果提到了:11TFLOPS单精度,22TFLOPS半精度,显存带宽400GB/s,性能为目前iMac最强GPU的三倍
不清楚这里是按照哪款算的
1.如果是按照Vega 56计算
那么频率为1535MHz左右,这和Vega FE、Radeon Instinct MI25的频率都很接近

2.按照Vega64计算
频率就会有明显降低,为1342MHz左右
同时按照400GB/s计算,HBM2显存频率为1.56Gbps。
前代iMac最强GPU是Radeon R9 M395X,Tonga架构,2048SP,频率909MHz,搭配256bit [email protected]
单精度3.72TFLOPS,三倍差不多就11TFLOPS
有人可能会说3倍TFLOPS不等于3倍性能
还会说AMD的TFLOPS不等于NV的TFLOPS
这就要和下面的内容有关了
Vega上,AMD的TFLOPS和实际性能会比以往接近得多。
ShaderEngine是在第二代GCN被引入的。
包含了几何引擎、光栅/ROP和L1缓存


Tonga的架构图,可以看到4个SE以及具体组成

GCN CU架构 图源:PCWATCH
在AMD前几代GCN架构中,高端一直都维持着4个ShaderEngine
即便到后来Fiji上4096SP之多,依然还是4个SE

这是有原因的
在GCN设计之初,AMD就认为未来的游戏将会更偏向于计算,而不是几何
所以GCN更偏向于计算,而且对于HPC/GPGPU应用来说,增加SE会大幅增加额外面积和功耗
Hawaii(R9 290X)上4SE还算比较平衡,每个SE内有11CU
但到了Fiji,SP数量猛增至4096个,SE依然维持在4个 – 每个SE下就有16CU
这样的设计可以说不太平衡,甚至有些“畸形”。【个人看法】

Fiji依然是4SE

Fiji die shot
计算方面倒还好,8.6TFLOPS的数字很好看,OpenCL等计算应用也能比较有效的利用
普通用户比较关心的游戏方面,4个ShaderEngine,也就是只有4个几何引擎的瓶颈就十分明显了
前端只有1个几何引擎+光栅引擎,导致瓶颈
FuryX很多时候空有TFLOPS(理论性能),而实际性能不如低得多的NVIDIA GPU,大量的计算资源没有用上,SP处于闲置状态。
这也是目前GCN的普遍情况,TFLOPS比同等级的NVIDIA GPU高得多,实际性能却没什么差距【DX12有所改善】
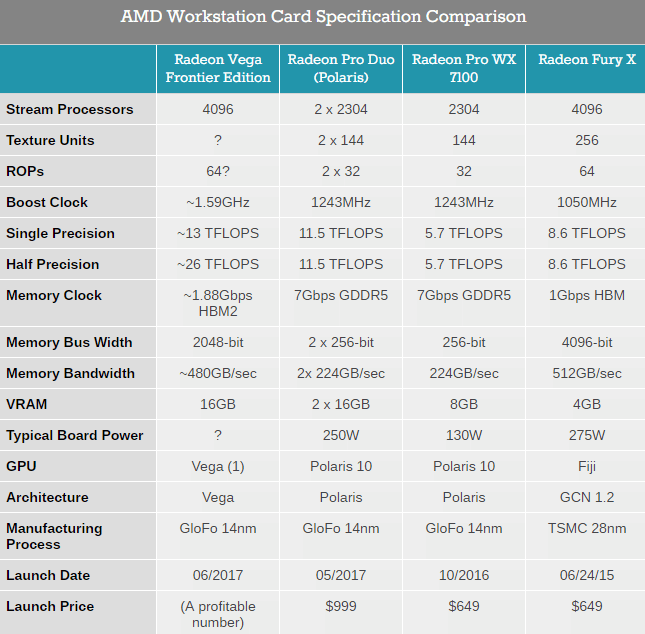
理论数据上Fiji并不差
但….
在Vega上,这样的情况将会有所改变。
Vega将从偏向计算转回到兼顾计算和几何的平衡架构
下面是Vega 10的“die shot”,AMD市场部管理 Scott Wasson说不是真正的die shot,而是Marketing


这种图在之前Polaris的官方白皮书中也出现过,和真正的die shot有些区别
但也给了我们很多信息。

可以对照一下Polaris10,die shot来自reddit

看此图建议将手机/屏幕/脖子旋转90度
可能Shader Engine从祖传的4个变成了8个,也就是每个SE内有8个NCU【只是推测】,这样的话每个SE内的NCU减半,大幅降低前端的瓶颈,几何引擎也会增加到8个。
也可能依然保持4个SE,但管线会缩短,依然是为了更充分利用计算性能
Vega将会是一个更平衡的架构,以往GCN前端的瓶颈会大幅减少,理论性能【TFLOPS】能够得到更完全的释放

图中NCU之间的那道黑色的不知道是什么
如果是如图分为8个SE的话,几何性能有点太强
相比Fiji,Vega10要平衡的多得多

改进的负载平衡
这些前端在原来基础上也有了很大改进
Vega新的几何管线通过引擎间更好的负载平衡和新的Primitive Shaders,带来了更高的每时钟输出(IPC),而开发者不需要对程序做任何改动。
AMD官方的数据是:Fury X上4个几何引擎每周期最多生成4个多边形,而Vega上的4个几何引擎能够生成11个,2.6倍的提升。
Primitive Shaders不需要开发者改动代码,工作应该就在AMD的驱动这边了
Vega翻倍的几何引擎带来的性能已经很强,如果还需要更多的性能,估计可以对游戏针对性优化
因为Vega设计需要考虑到的一点就是NVIDIA的Gameworks等游戏:这些游戏的很多功能/特效在A卡上会带来大量性能损失,造成瓶颈,这是NV的策略之一
而Vega就需要克服这些不利因素,所以有了大幅加强的几何引擎和性能,基于曲面细分的那些特效在Vega上性能会很好。



总而言之,有了以上的各项改进,可以期待Vega能在游戏中带来与NVIDIA同等理论性能【TFLOPS】GPU相近的性能。
来源:Anandtech/PCWatch/Youtube@NerdTechGasm/AMD/Reddit/HardOCP
本站整理内容,转载请注明出处。
如果有错误请批评指正




imacpro上的vega理论上是不是可以用于笔记本
@wangbaisen1990:iMac用的500系的话官网写的就是Radeon Pro Mobile
但是Vega就不清楚了,Vega10可能太大,275W的TDP
Vega11还是有可能的
@剧毒术士马文:如果大幅度降频的话会不会能塞进去
@wangbaisen1990:那为什么不用Polaris/Pascal/Vega11呢
FuryX系列就没上笔记本的
@剧毒术士马文:这和友商的Max-Q设计差不多,先降核心电压再降频,芯片是纯电阻电路,按W=V平方除以R,七成功耗获得九成性能。580M才65w,也有八成桌面版性能
@在amd看大门:HBM2散热,如果是G5还好说
而且Vega10的die size和GP102都差不多了
Vega11上笔记本会很容易
友商 gg(NV≠友商
这么说VEGA不愁性能了?那为啥还遮遮掩掩的啊…
@Mikiya:产能。
另外Linux驱动没准备好。
Polaris那时候Linux用户也是开箱即用的,开源驱动已经就绪了。
有苹果这手笔
vega回本不愁
按照anandtech讨论的结果,290X是这几年前后端搭配最合理的芯片,肥鸡纯粹是看不过980ti而强行给Hawaii加长了一截,又赶上amd首次做600mm大芯片结果太过臃肿。Vega现在倒是抱住了果子这条腿,出货量至少没肥鸡失败
@在amd看大门:前后端搭配最合理的没算上Pitcairn
SP效率秒掉老大哥Tahiti啊 同样都是最早的gcn
@theLastWish:7850是一代神卡。
Gtkperf这种纯2D测试7850拉着AMD全家老小一起A。
Vega目前不支援GDDR5/GDDR5X是最大失策,不然估計可以更早出貨跟NV的TITAN Xp競爭。當然想到Zen微架構也跳到今年才出貨,本身可用的開發資金就比較緊張也是挺無奈…
@以Porsche之名:Vega的HBCC也是很重要的一項特性,如果要支持G5/G5X就要新的IMC了
本身AMD的產品很好,但執行力……
@剧毒术士马文:最主要還不是缺錢…另外與技術無關的是,AMD的行銷能力確實要提升一下
AMD在过去的架构上过于注重运算性能了,相比几何和光栅,填充了数目惊人的流处理器。四个Shader的Fiji的每个管线都过长,使得运算任务很难充分填充每个Shader中的流处理器,而前端数目稀少(每个shader仅有一个)的几何和光栅则更加限制了它在游戏中的发挥。因此相较于NV,AMD需要更高的理论运算性能(TFlops)才能达到和NV同样水准的游戏帧数。而现在的八shader让每始终的几何运算能力直接翻了一倍,游戏中能更加接近他们理论的TFlops水准。这对于游戏玩家而言是个绝大好消息,因为至少不用担心delay半天就是个超频Fiji了。(祖传4Shader的原因应该是几何和光栅在HPC和GPGPU中都没有作用所以觉得可以不要)
@gnattu:已经补全内容