19/01/24: 更新了Zen 2 Matisse 的相关解读,中文/日文版之后更新,先只更新英文版(懒)
来自Userbenchmark
测试分数参考意义不大。
很多人看到32M 90ns延迟认为12C只有32MB L3
我个人不这么认为,L3应该是64M
这种情况下大概只有一种解释



8/12/25: 更新了 Zen2 Matisse 的信息和关于缓存代号的个人推测
18/11/22: 更新了 64C Rome的信息
18/11/21: 更新了Picasso/Raven2的步进信息
18/11/19: 更新了日文版 because why not
18/11/18: 加上了中文版和部分说明,为了便于群众理解,翻译有做调整
接下来的这段时间应该会有大量类似工程样品信息流出。
所以就重新做了一下排版,修正了一些错误
增加了部分新型号
之前做的被“引用”的比较多,所以加了个比较大的水印。
English Version:

更新的部分放大版:

中文版:

日本?版:

配合我的路线图食用更佳
My AMD Client Roadmap 2017-2020

AMD Ryzen Processor Product Stack 18Q4
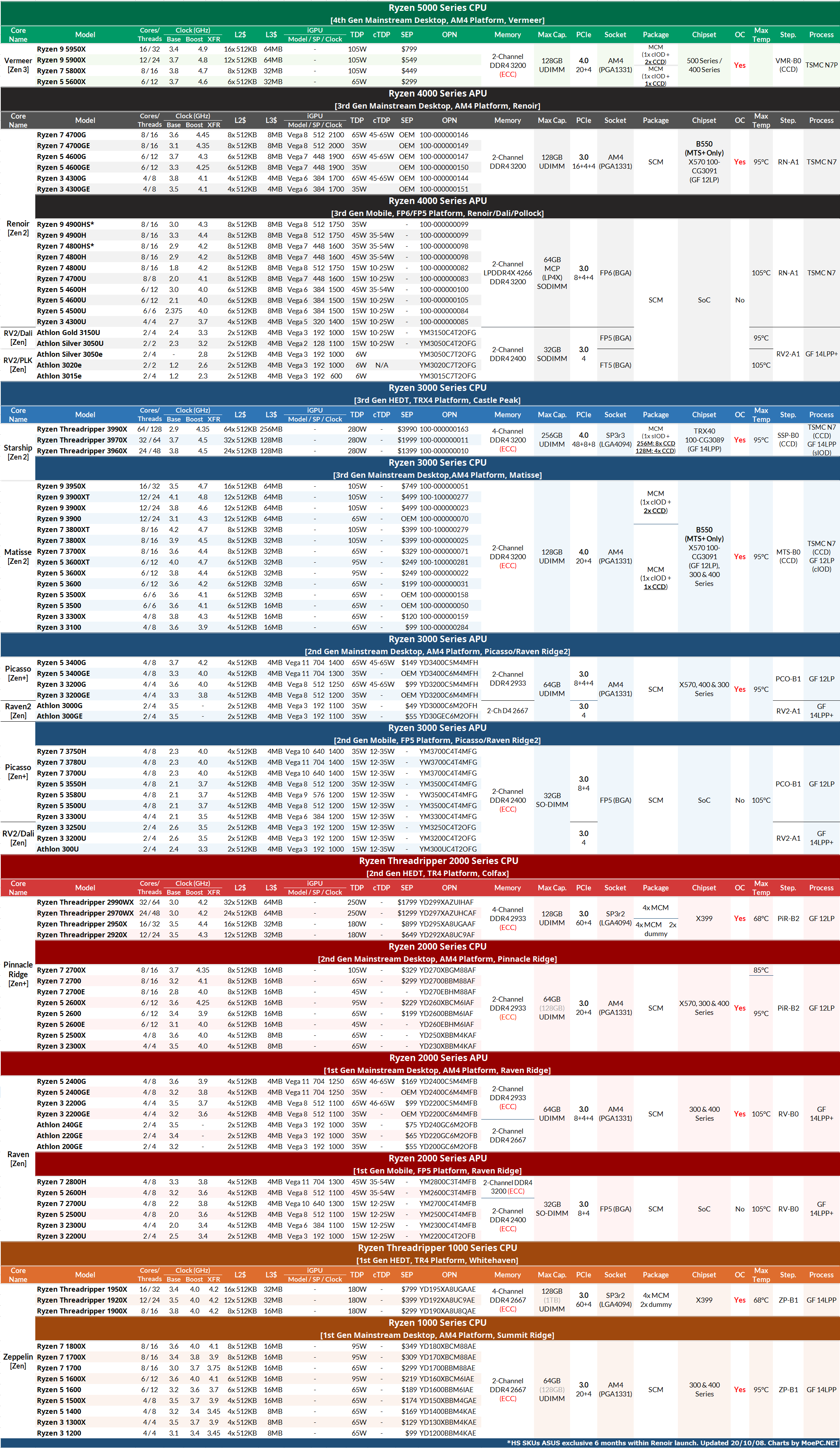
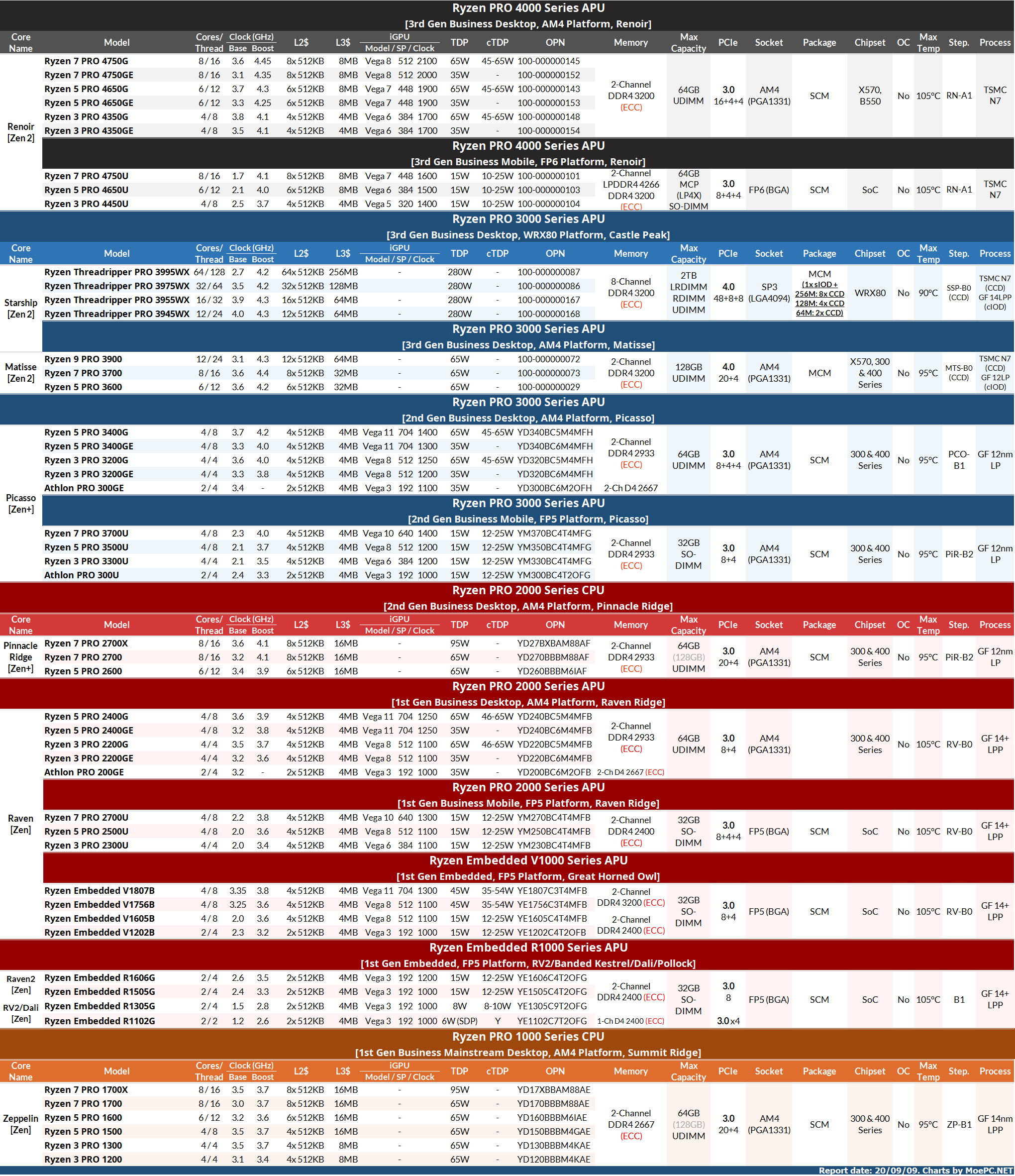
AMD Ryzen PRO/Embedded Processor Product Stack 18Q4
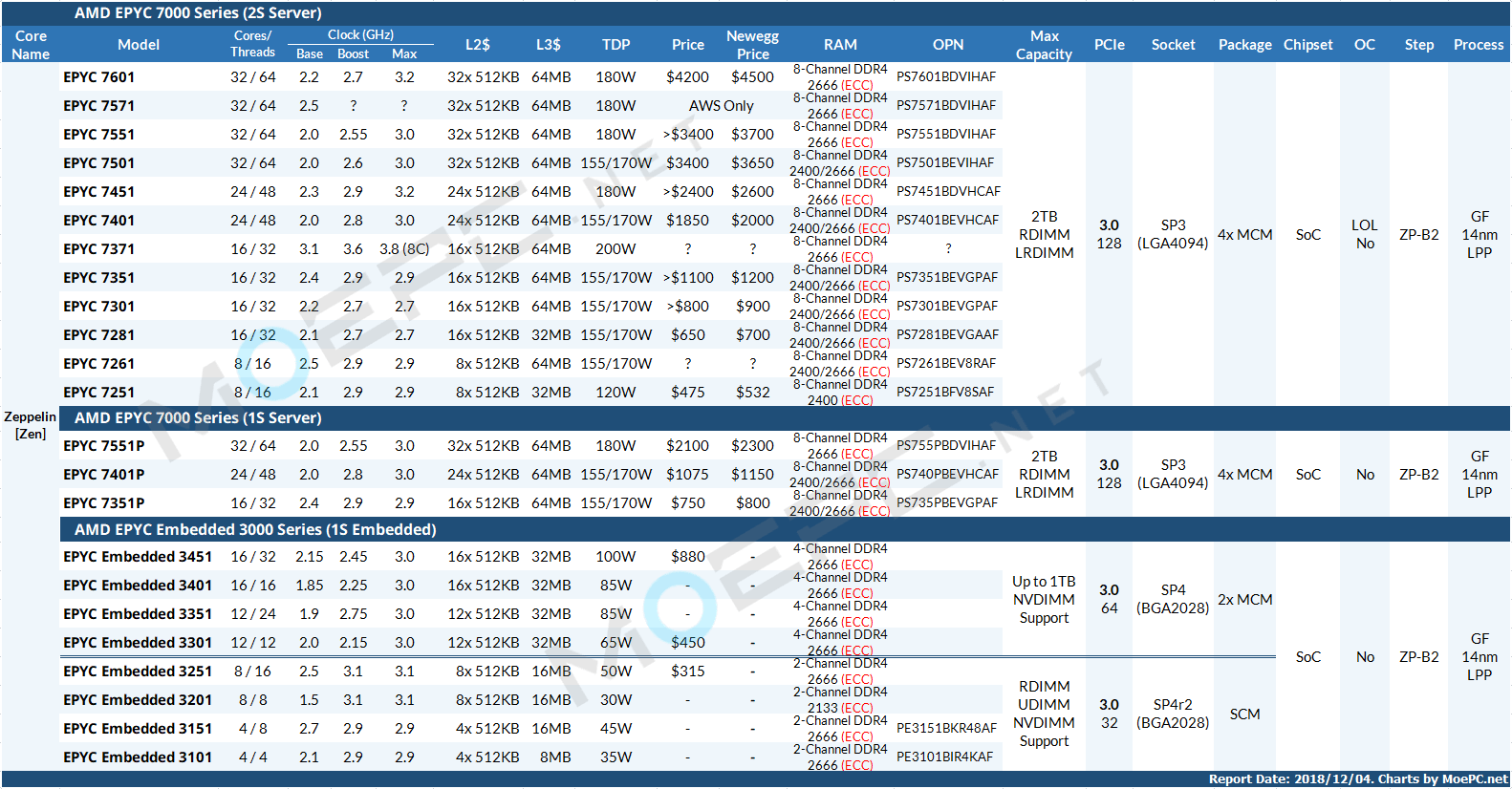
AMD EPYC Processor Product Stack 18Q4




https://ranker.sisoftware.co.uk/show_run.php?q=c2ffcee889e8d5e2daead2e6d1f785b888aecbae93a385f6cbf3&l=en&tdsourcetag=s_pctim_aiomsg
ZS1711E3VIVG5_24/17_N
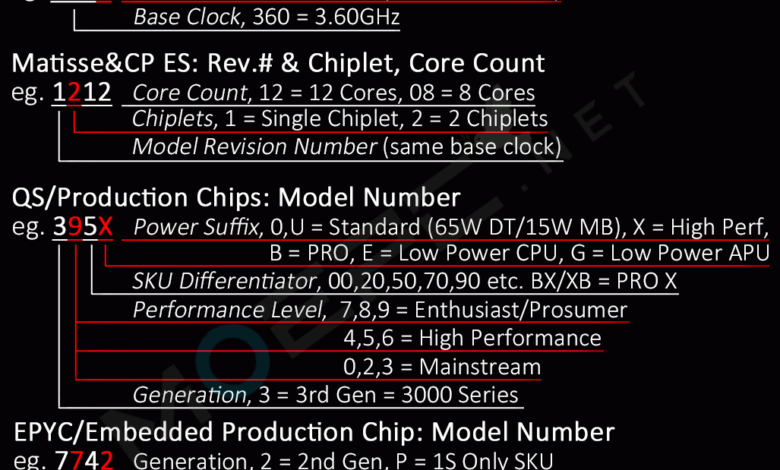
来,解读下2DS104BBM4GH2,其实除了那个S,都能看懂。
@柯基:好像是之前爆出来过的
中文版持续鸽子
不对,这么看应该是不同chiplet的l3不共享。。。。。
这延迟测试是从一个核心上开始的吧,这就解释得通了,在一个ccx 16mb以内延迟很低,过了之后在32mb之内还是一个chiplet,延迟因为跨ccx但有核内if连接延迟只是逐步提升,过了32mb就要过io die来进行了,延迟自然跑上去了,但也没有和内存延迟挂钩,(有延迟下降的部分)这就是第二代if的特征?
@滴5号:大概迟了一个星期
@剧毒术士马文:不好意思没懂迟一个星期是什么?
佛了,我用公司电脑百度搜meopc翻六七页下去找不到,bing第一条就是。
@XYun1996:不想随时挂梯子就用bing,给老人推荐搜狗搜索,翻车概率小一些
@XYun1996:Bdsm
某舅妈又在爆蕾妻和naive的料了。。。
naive今年应该憋不出来吧?
@xing0999:那几句模棱两可是个人都知道的旧消息也敢叫“技术细节”hehe
这不叫爆料
这叫复读+造谣。
@剧毒术士马文:我想看农企临时工翻身,不想看大V吹牛皮
C#程序 https://github.com/asadityas67/RyzenCodeDecoder
目前其实最大的悬念是IO die内部采用IF环还是crossbar连接
这个东西决定了到底这玩意儿的拓扑是不是一个单纯的星形
@柯基:IF Ring这个东西并不存在。
建议先把AMD给的IF技术细节看一遍。
有个问题一直没弄懂
Core2Quad的2x6M L2也是和Zen一样的是victim cache吗?
有没有消息Zen3用cowos封装?
这代IF速度是和内存解绑了吗?希望最终版的IF速度能再高一点……(潜伏更低)
EPYC的IO die设计也能完全证明我这个说法,8组IF出口,对应链接8个Chiplet的IF环
“不同城市之间的绕城高速,再用高速公路连接上”
AMD只是想努力节约成本,phy占用的面积太大了,用7nm不合适。
你微博上面那个示意图一定是有问题的。
Chiplet和IO die内部都有独立的IF环,环与环之间用IF再链接。
不然同Chiplet异CCX访问还走一道IO die,这样设计是非常不合理的。
@柯基:这只是我昨晚5分钟做了个图罢了
很多想的东西还没加进去。
有文章在准备。
这个延迟说明了L3$既不是32MB Unified也不是64MB Unified 而是4(CCX)*16MB seperated,而且不同CCX互不共享(笑)
@久保带人:什么时候Zen的L3成Unified 的了??蛤?
都9102年了,这么低级的问题我还以为对于本站读者而言不需要明确点出?(几万-几十万个人就你一个出现了这么奇怪的理解
只是有人还在认为总容量32M 每CCX 8M罢了,一直都说的是总容量。我去年到今年说了不下5次4C CCX 每CCX 16M,在哪里脑补来的我说的Unified?
而且其他地方没有任何人有和我一样的说法。甚至还有大片认为是8C CCX。从去年到今年,大概只有我一直在告诉你们说是4C CCX(去年很多人还说我造谣hh),谢谢。这个代号解读也是我从17年更到现在的
你看到的爆料泄漏分析可以肯定的说源头都是我这里,或者有些人看了我的文章拿去改个说法当自己的。(笑。
另外“不同CCX互不共享”也是错的。
@剧毒术士马文:为先前的唐突暴言表示抱歉。
先前看Latency Ladder的看错导致部分理解错误,将16MB Latency开始提升当成了Latency到达最大约100ns(32MB时),也就是说同die的两个CCX的互联延迟相比前代有所改善?但是在不同Die CCX的延迟还是偏高一点?所以64MB时的延迟已经几近内存延迟了。提出unified这个问题还是从ladder来看没有从另外一个die的两个CCX的缓存提取的行为。
关于不同CCX之间共享的机制个人了解甚浅,唐突发言。
关于马文大佬的消息的准确性和及时性,鄙人未有过质疑(关于CCX核数缓存大小)。鄙人也未听信所谓来源不明的小道消息。所有发言皆来源于本人个人的臆想。
对于之前发言的再次表示抱歉
@久保带人:那个是别人脑补的,之前贴吧有个键盘工程师一个劲跟我讲这个,讲的我脑子疼
w是12x256l2+64l3?
内存延迟不好看咧
@路人:CL19 2666的条子延迟是这样的,而且这个软件未必对zen2的测试准确
@potato:起码那曲线表现了CCX缓存16M,内存延迟嘛,条子烂是原因之一,其二就是外置MC导致的延迟增加是不可避免的。
@路人:今天看到了个9880H的延迟,双通道3200依然有86.3,这鸟软件测试延迟根本就不准确
真希望這次能給力點。
内存缓存性能解读求求,,,
桌面版Ryzen 1000系列是否还在产?
我正在使用谷歌翻譯發表評論,因為我不能在這個網站上發布英語,所以我很抱歉語法。
我的問題:
最後一個“_Y”是什麼意思? 我也見過“_N”。 這是關於產品的最終決定,“是”還是“否”?
謝謝
@Rapta:First of all, this site prohibits engish-only comments as an anti-spam setting (see buttom of the page). You can just copy a chinese character (for example, 中) and add it in your comments to send them out.
Then regarding the question you are asking, I don’t know either, so maybe you can directly reply (“回复” in Chinese, click those characters at the right-hand side of each comment to reply) to one of the comments sent by the author (ID: 剧毒术士马文) to get more information.
@changsy212:See that. Cheers.
中
所以这次修改添加Matisse是看到Matisse的ES了的意思吗……
@potato:是啊
8C 3.7 32M
@剧毒术士马文:所以今年9月份的那个传闻RTG收到8C base4.0 boot4.5的样品是假传闻?
@喵控:那个显然不是真的
@剧毒术士马文:@剧毒术士马文: Do you know what the suffix “_Y” means? I’ve also seen an “_N”. Is it perhaps to signify specs finalisation with a “yes” or “no”?
@Rapta:I don’t think so because I have yet to see a single EPYC that ends with “Y”.
And the leaked Rome QS also ends with “N”,this one should be a low power SKU (thus I flagged it as 64C LP Rome) and is close to final.
The “Y”surely indicates the sample is pretty close to final specs, at least all samples I’ve seen are QS.
I have my own theory about this but I’m not really sure about it
马文桑复更了!喜大普奔
图中第一个8没表达清楚。
还是不知道单CCX有几个核心。
@ayu:我以为这已经够明显了就没作多余说明
就一位
1-9代表核心
10以上用字母代替
@ayu:之前曝光过ROME的三级缓存是16M X 16,64除以16不用我多说了吧
期待一个YM3601C4T8KF44036_Y