Anger是著名第三方X86_64处理器优化指南的作者。
The microarchitecture of Intel, AMD and VIA CPUs
An optimization guide for assembly programmers and compiler makers
By Agner Fog. Technical University of Denmark.
AMD的Ryzen处理器采用了全新设计的CPU微架构,属于第一代“Zen”架构处理器。不得不说新架构的设计相当成功,使得AMD在落后这么多年后再次能与Intel竞争。
Ryzen的micro-operation cache 微指令缓存容量为2048条micro-op或指令。对多数程序关键的最内层循环是足够的。很多人讨论Ryzen每周期到底能执行4条还是6条指令,因为AMD的文档也没有明说。不过根据我的测试显示,既不是4条也不是6条,而是5条。只要代码是从微指令缓存运行的,每周期就能执行5条指令,而Intel只能执行4条。无法放入微指令缓存的代码则通过传统的code cache代码缓存,每周期最大可执行4条指令。
然而从代码缓存提取指令的比率不是部分文档记载的32字节/周期,而是在16字节/周期左右。我目前看到的最多为17.3字节/周期【SMT?】。由于大多数向量化代码长度都在4字节以上,可能会有瓶颈。
1条比较指令和1条条件转移指令可以融合为一条微指令。所以在执行小循环的时候,每次循环是有可能达到6条指令/周期的。除小循环之外,1条执行转移的转移指令需要两个周期,不执行转移的每周期则可以执行2条。
256bit 向量指令(AVX指令)会被拆分为2条128bit的微指令。AVX指令在微指令缓存中只占1项。还有其他一些指令也会生成2条微指令。在解码器之后微指令队列的最大吞吐量为每周期6条微指令。这个队列出来的微指令流会分到10条管线:4条使用通用寄存器的整数操作管线(ALU),4条浮点/向量操作管线,以及2AGU。如果将整数和向量指令混合,就可能达到6条指令/周期的吞吐量。
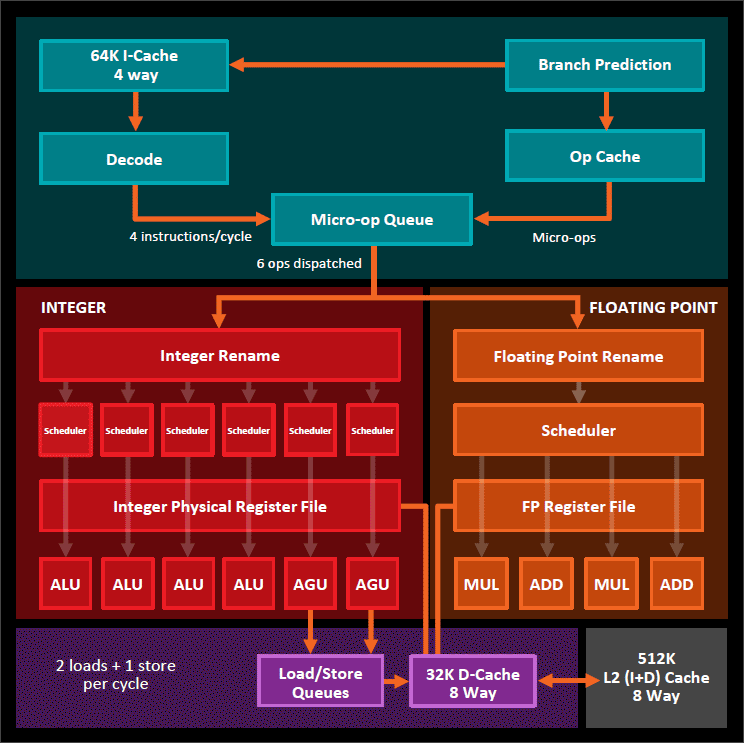
让我们比较一下Ryzen和Intel处理器的执行单元。Zen架构有4个128bit 浮点/向量单元,2ADD+2MUL。而Intel有2个256bit单元,既可以作ADD也可以作MUL。这意味着带最多128bit向量(AVX)的浮点代码在Zen上每周期最多可执行4条(2ADD+2MUL),而Intel只能执行2条。到了256bit向量(AVX2),AMD和Intel每周期都是2条。Intel在256bit融合乘加指令(FMA)上要强过AMD,因为Zen每周期只能执行1条,Intel可执行2条。在256bit内存写入上Intel也要强于AMD,因为Intel有1个256bit内存写入端口,AMD只有1个128bit。马上Intel处理器就将支持512bit向量,AMD可能要更长时间。
然而市场上绝大多数软件的更新速度要落后硬件好几年。如果软件只使用128bit向量,Ryzen的性能会相当不错,AMD每周期可执行6条微指令,而Intel只能做4条。不过每周期执行这么多指令就会带来问题:如果第二条指令依赖于第一条指令的结果,这两条指令就不可能同时执行。为了避免这类情况,处理器的高吞吐量就给程序员和编译器带来了更多压力。想达到最大吞吐量就必须同时执行大量独立指令。
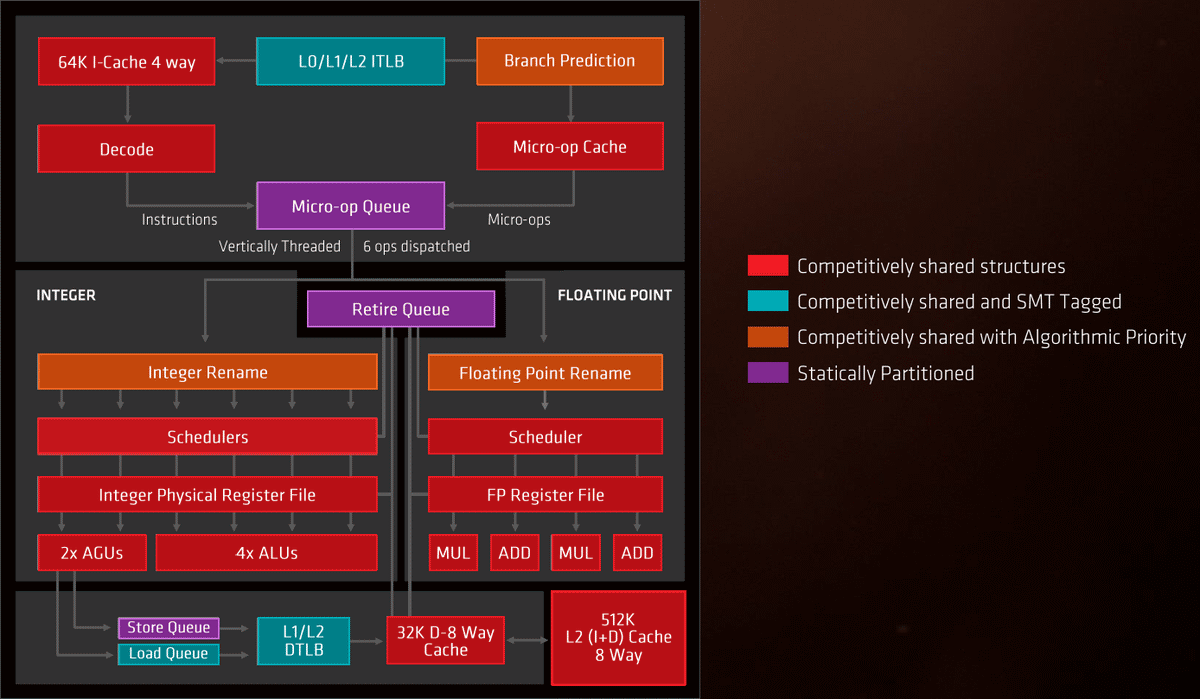
所以我们有了同步多线程SMT。在同一个CPU核心上可以同时运行2个线程(Intel称之为HT超线程)。每个线程会得到一半的资源。如果CPU核心的容量高于单个线程可以利用的范围,运行2个线程就有道理。在Ryzen上的SMT带来的整体性能提升比Intel处理器高得多,因为Zen核心的吞吐量要更高,高于之前所有的AMD和Intel处理器(除了256bit向量)。
Ryzen的节能非常激进。未使用的单元被时钟门控,频率也根据负载和温度大幅变化。在我的测试中,磁盘读写为瓶颈时频率可以低至标称频率的8%,而运行连续的CPU密集型长代码时频率可以高至标称频率的114%。由于温度原因,这样的高频率在八核全开时不可能达到。
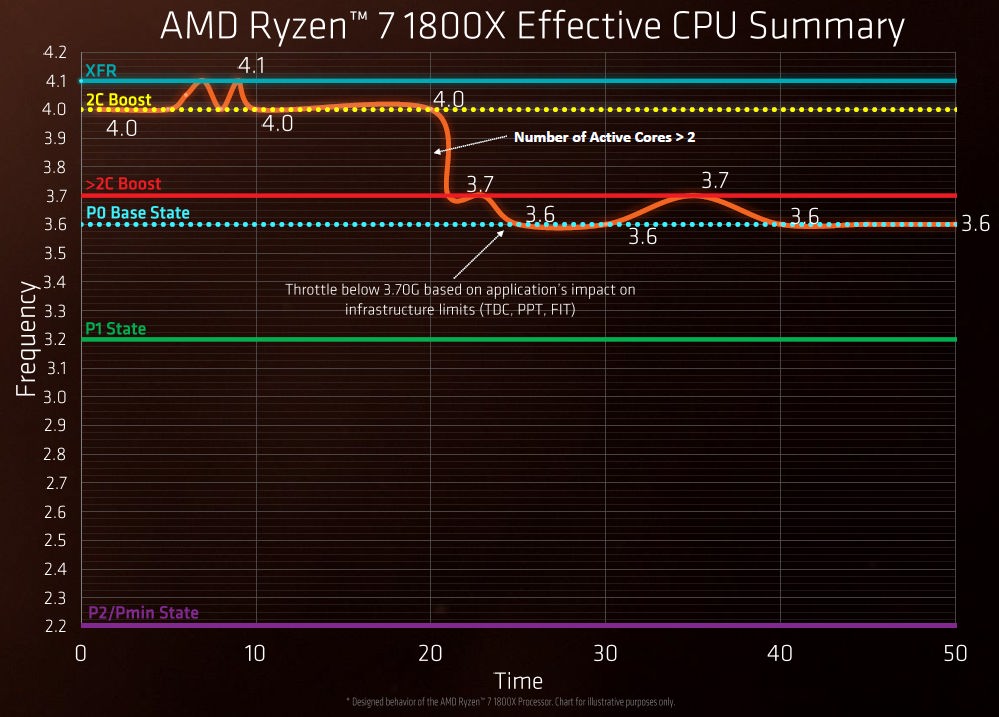
不断变化的主频对于我的性能测试是一个大问题,因为不可能测量出精确且可重复得出的计算耗时。先用连续的CPU密集型代码预热处理器会带来一点帮助,但得到的频率依然不够精确。时间戳计数器TSC用来测量少量代码的运行时间,它在Zen上却是根据标称频率测量的。Ryzen有另一个计数器,称为Actual Performance Frequency Clock Counter (APERF) ,类似于Intel处理器的Core Clock Counter。不幸的是APERF计数器只在内核模式才能读取,而TSC在用户模式就可通过测试程序读取。我不得不用如下方式计算实际频率:运行完一次测试立即用驱动读取TSC和APERF的计数。用这种方法获得的TSC和APERF计数被用来校正测试中读得的TSC计数。这个方法很尴尬,结果却很精确(除了频率大幅变化的测试)。
AMD处理拓展指令集的方式与Intel不同。AMD一直在不断增加新指令,如果没多少人用就把它们移除;Intel则一直在保持对旧指令的支持。AMD在推土机上引入了FMA4和XOP指令,还有打桩机上一些并非特别有用的TBM指令。现在他们把这些都移除了,XOP和TBM在Ryzen上不再受支持。FMA4官方宣称不支持,但我发现FMA4实际上在Ryzen上工作正常(即便CPUID指令也显示不支持FMA4)。

【官方GDC文档】
via:http://agner.org/optimize/blog/read.php?i=838
本站编译,转载请注明出处。
附:从手册中节选的部分内容
浮点执行管线


AVX指令

Zen内核

Ryzen的瓶颈


以及Agner对Ryzen的指令吞吐量、延迟等做的全面测试表格:




















Agner的CPUID mask教程是我最喜欢的部分。
可以把牙膏厂CPU伪装成农企的。
这篇技术文是我最喜欢的,反复看了好几遍了。
@ayu:到原作者的博客里看,还有更多
比如Knights Landing、Bulldozer、SandyBridge之类
指出的Bulldozer的缺点正是后来Steamroller、Excavator改进的地方