原创,总结及翻译,转载请注明出处。
目录:
本文基于Anandtech上最新发布的文章AMD Carrizo Part 2: A Generational Deep Dive into the Athlon X4 845 at $70
文章通过对几代APU平台Athlon的深度解析和同频测试,对比得出这几代架构效能的提升。
这几代时间跨度为2012-2016年。
由于Carrizo和最新发布的BristolRidge在架构上是完全相同的(BristolRidge多了DDR4的IMC)
都采用Excavator挖掘机架构,挖掘机的整数核心可能是目前最高效的整数核心之一。
所以这个测试也可作为代表BristolRidge和整个挖掘机架构的测试,给整个推土机家族画上了句号。
2016.9.23更新:按照目前拥有的BristolRidge的曝光来看,BristolRidge提升主要有:
1.DDR4内存+高频核显带超过20%的图形性能提升
2.工艺改良,CPU部分超频潜力比Carrizo要高,1.325V可达4.8GHz


AMD最新的X86架构代号为Excavator,采用了第四代推土机核心:Carrizo核心。Carrizo和Excavator的首要目标是移动平台。今年二月份我们测试了15W的移动版,晚些时候AMD发布65W桌面版的时候我们马上来了一颗进行对比测试。我们将测试Athlon X4 845和它的大姐姐们:SteamrollerB架构,Kaveri核心的X4 860K、改进版Piledriver架构,Richland核心的X4 760K和原版Piledriver架构,Trinity核心的X4 750K。
AMD未来的主流市场
AMD和Intel作为主要的X86处理器制造商,把消费产品细分为三个等级:高性能、主流和入门级。正如字面上一样,这些产品以性能、价格和功耗来分级。但AMD这边高性能产品已然没有什么竞争力,还停留在2012年。主流市场是AMD当前的营收来源和市场份额。与高性能CPU不同,主流产品都集成了显示核心。目前AMD的APU图形性能相当于50-80刀显卡的性能,比较适合低端电脑。带集显的处理器在移动平台表现很好,因为节省空间,节能和降低价格更加重要。
有部分买了主流产品,但想要独显的用户经常对这不得不为之付钱的集显感到不爽。对于这些购买150刀以上独显的用户,买个带集显的CPU之后,集显部分就变成了没用的辣鸡,并且他们也不想付出这部分强加的成本。AMD曾经推出过Dual Graphics交火来让集显有点卵用,但这需要驱动和游戏的良好支持。DX12可能会带来一些改变,但这同样需要驱动和游戏支持。那么为什么要为集显付款呢?Intel没有给你多少选项,配个高端平台至少也要450刀。但AMD给你带来了Athlon产品线。

APU产品线是AMD的桌面主流,每代都发布几款。除了APU,AMD也发布纯CPU的Athlon产品线。他们的设计和APU相同,但集显部分被鸽掉了。从技术上来说它们仍保留了那部分内部芯片,但由于瑕疵或者库存管理,从物理上被屏蔽了,同时价格也大幅下降。这个方法并不新鲜,很多处理器设计都有这样的情况 – 当处理器被生产出来,它们都有一个天然的良品率(高良品率的工艺会被称为“更成熟”的工艺)。如果有瑕疵的部分是可以屏蔽的,AMD这样的公司就依然可以把它以低价格卖出去,而不是直接扔掉。这部分省下来的钱对于用户来说可以升级其他部分。
AMD Athlon X4
对于DIY的老司机们来说,Athlon速龙这个名字,能唤起关于AMD春风得意的那个年代的回忆。APU发布之前,大多数主流产品都冠以Athlon的名号,从单核到四核。K10的高性能处理器改叫Phenom羿龙,旗舰FX,同时还有一些低端的Sempron闪龙。
自从2012年Q4转向推土机架构后,AMD每代都保留了小部分AthlonX2/X4型号。这次评测我们每代都选择一颗并做相应测试。
下面的表格显示了2012年以来AMD发布的所有纯CPU处理器。信息来源于不同渠道,大部分来自于CPU-WORLD,AMD CPU WIKI,但奇怪的是没有官方来源(像Intel ARK那样的)。


X4 845是桌面平台唯一的Carrizo产品。虽然有报告说X4 835这个型号存在,但没有任何消息说这款产品实际存在或者发布。Carrizo的APU没有桌面产品。
X4 845实际上是笔记本APU的桌面马甲,因此有一些物理上的限制:比如只有8条PCIe3.0
从Richland到Kaveri,L1指令缓存增加了50%,每模块64KB变成96KB,2way关联变成3way关联,具体原因可以在前面的推土机评测中找到。
从Kaveri到Carrizo,L1数据缓存增加了一倍,每模块32KB变为64KGB,4way关联变为8way关联
X4 750K既有Trinity版本,又有Richland版本。但想找到后者很困难,因为后者仅供OEM。
Carrizo每模块仅有1MB L2,四核共享2MB,然而之前的架构每模块都有2MB L2,四核共享4MB。
Carrizo简述

线程调度更好了,并且频率/电压调节机制也有改善

在金属叠层的改动是的整块芯片在设计上更接近于GPU,晶体管密度更高,而且能效更好。

Excavator挖掘机,是AMD发布推土机架构以来最大的一次架构升级。Excavator的逻辑单元经过了重新设计。这不是为了提供更高的性能,而是为了缩小核心面积,AMD几乎是从头开始重新设计的。这使得Carrizo的核心面积显著缩小,代价是一点点超频潜力,但这也带来了功耗的降低。

AMD的目标是双模块Carrizo移动版功耗为15W,高端产品还提供35W的Boost模式。

在TechDay,AMD小心翼翼地点出,在35W时,Carrizo的效率、性能将和Kaveri相当,意味着此时唯一的提升是节能技术(以及集显的视频播放功能)。如果AMD的PPT是正确的,这甚至意味着高功耗情况下性能的倒退。【Carrizo只在35W以下时相对Kaveri有优势,35W持平,后被反超】为了测试这种情况,这次X4 845只跑在65W。
这意味着什么
虽然专为移动版设计,AMD依然决定发布一款Carrizo桌面产品。X4 845相对于移动版没有集显,还换来了更高的65W TDP和频率的小幅提升。而且还只有8条PCIE3.0。
一言概之,X4 845就是一个高耗低效版的Carrizo,性能与KaveriAPU持平甚至更差。IPC测试将会说明,Carrizo和Excavator将会是一次大的改进。
测试
Athlon X4 845, Carrizo 核心 Excavator 架构
Athlon X4 860K, Kaveri 核心 Steamroller 架构
Athlon X4 760K, Richland 核心 Piledriver v2 架构
Athlon X4 750K, Trinity 核心 Piledriver 架构


AMD Athlon X4 845, Carrizo (左)
AMD Athlon X4 860K, Kaveri (右)


AMD Athlon X4 760K, Richland (左)
AMD Athlon X4 750K, Trinity (右)
为了测试架构性能,所有处理器都锁在3Ghz。主要是为了考察单/多核性能以及新架构的改进。
然后是X4 845的超频。因为锁了倍频,超频空间会比较小,但我们仍想看看65W的移动版是否还有余地超频。
最后是同价位的性能测试。最明显的对手是G3258,主打超频的产品,价格72刀。我们也增加了APU来看性能有何不同。
测试平台
之前的测试都是以处理器默认支持的最大频率来决定内存,有人指出默认频率太低并且同价格有更高频率可选,然而很多家庭用户还是会使用支持JEDEC规范的频率,而不是改动BIOS或者XMP,所以独立的内存测试后面会放出。

测试项目
具体有如下几项
简单测试
简单测试直接混合使用熟知的程序,需要大概四小时。


WEB,综合传统测试
WEB测试使用Octane/Kraken +WebXPRT,综合传统测试使用CineBench和X264


详细专业测试
为了增加测试的深度,我们使用了我们的详细测试套件,综合了处理器频率、核心数、缓存、内存、架构的性能。还包括了FPGA负载。

游戏
游戏测试套件依然是15年的,都是有名的大作。WIN10+DX12的2016版套件还在开发中。


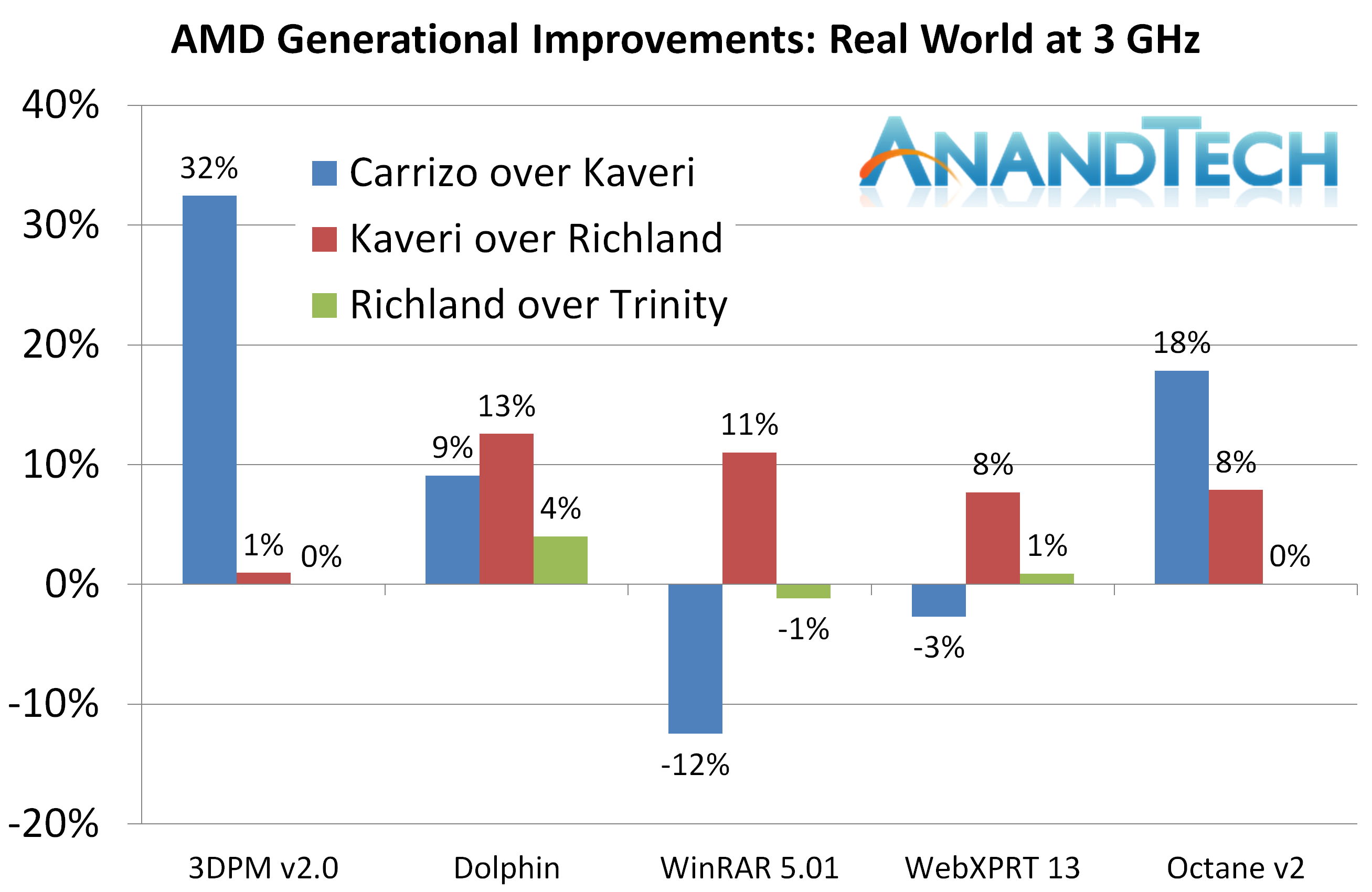
3Ghz实际性能
所有CPU频率都设为100×30=3000Mhz,内存频率均为默认支持的最大频率。


说到缓存,X4 845在L1上有很大提升,一般情况下能提高30%的缓存命中率。这会影响很多测试的结果。另一边,X4 845的L2被砍半,这会导致额外的延迟。
Dolphin Benchmark
大多数模拟器都依靠单核性能,Haswell在模拟器性能上有很大提升。这个测试模拟的是Wii的光线追踪程序,能够展现CPU的单线程性能。测试结果为分钟,Wii自身为17.53分钟。

由于架构优势,Carrizo领先Kaveri9%
WinRAR 5.0.1

WinRAR依靠内存带宽,Kaveri在这里很强。Carrizo的2MB L2在这里成为了最大的弱点。
3D Particle Movement v2

挖掘机带来了巨大的提升,主要归功于L1数据缓存。
Web 测试
WebXPRT 2013

这个测试很吃内存和缓存,Carrizo的2M L2再次中枪。
Google Octane v2

与上面的测试相反,Octane更能反映出执行部分的提升,这次Carrizo领先Kaveri 18%。
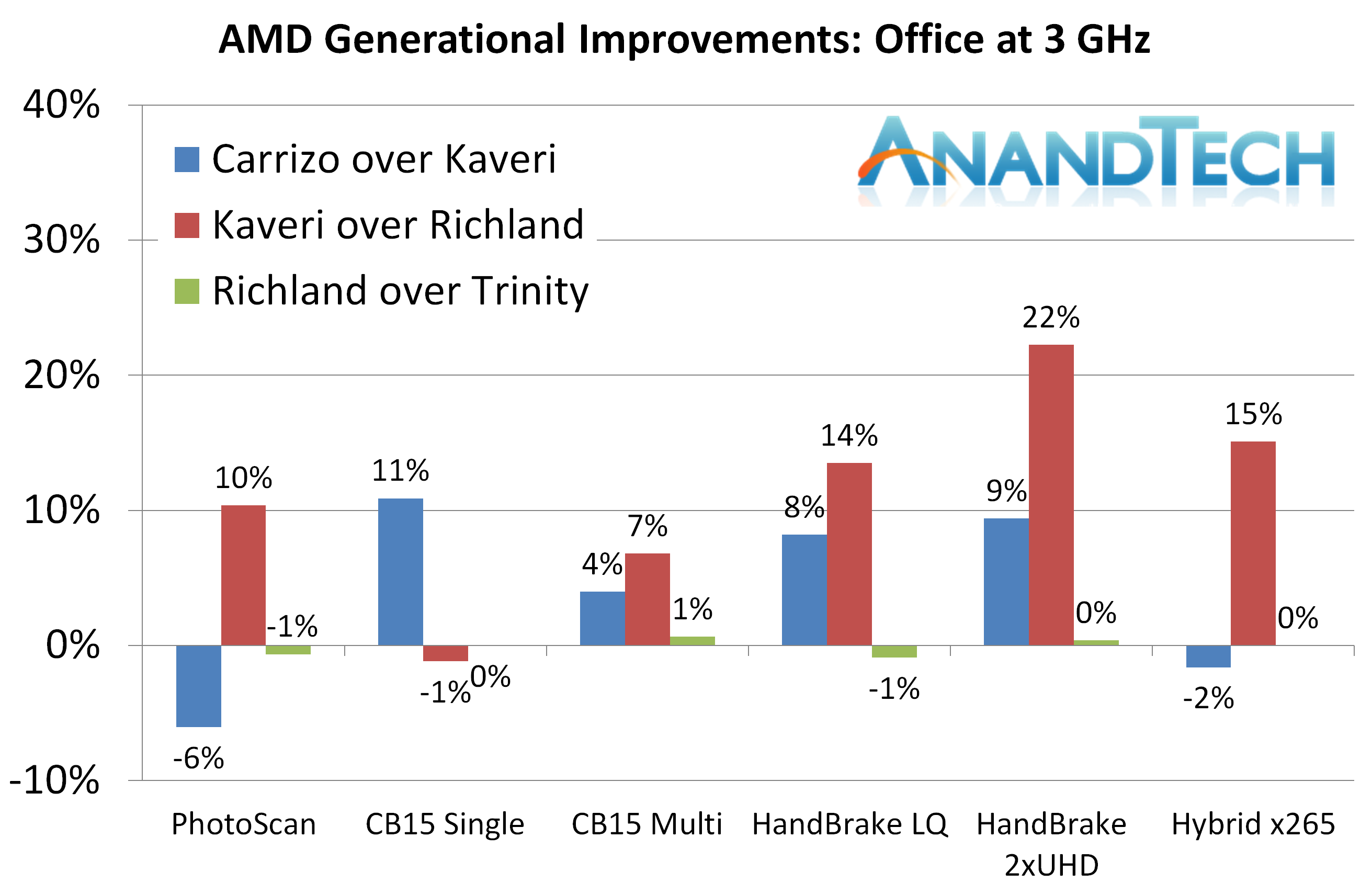
3Ghz办公性能
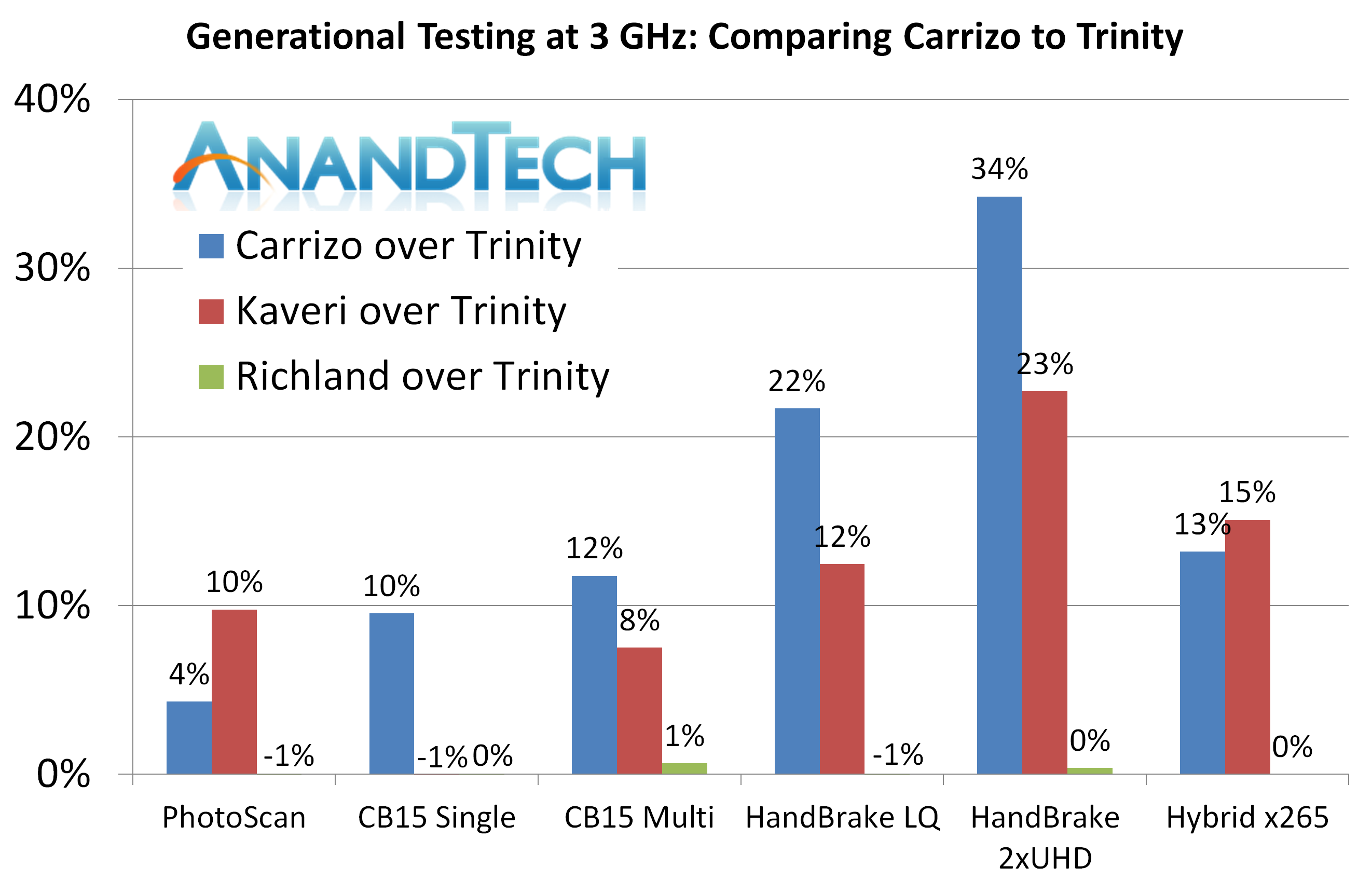
Agisoft Photoscan ? 2D to 3D Image Manipulation

Carrizo在Photoscan的第一阶段,读取图像时慢了下来,这需要大量的内存操作,Carrizo落后17%。在第四阶段Carrizo领先Kaveri,但总体上依然落后6%。
Cinebench R15


类似于Dolphin和3DPM,Carrizo的架构提升在这里很明显。
HandBrake v0.9.9


一般情况下这个测试更考验内存和缓存,但这次Carrizo相对Kaveri表现出了8-9%的领先。
Hybrid x265

然而X265下Kaveri和Carrizo差不多
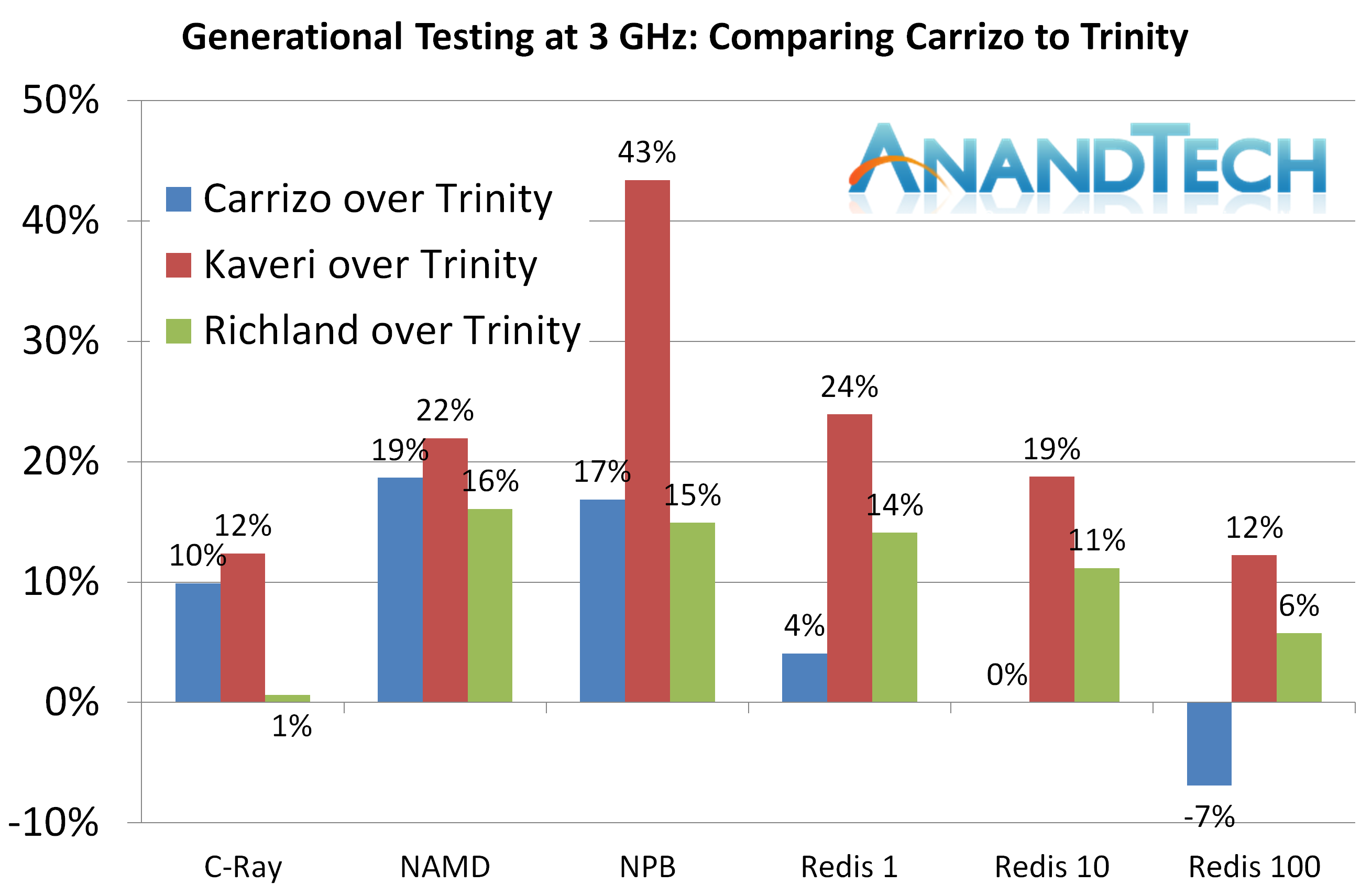
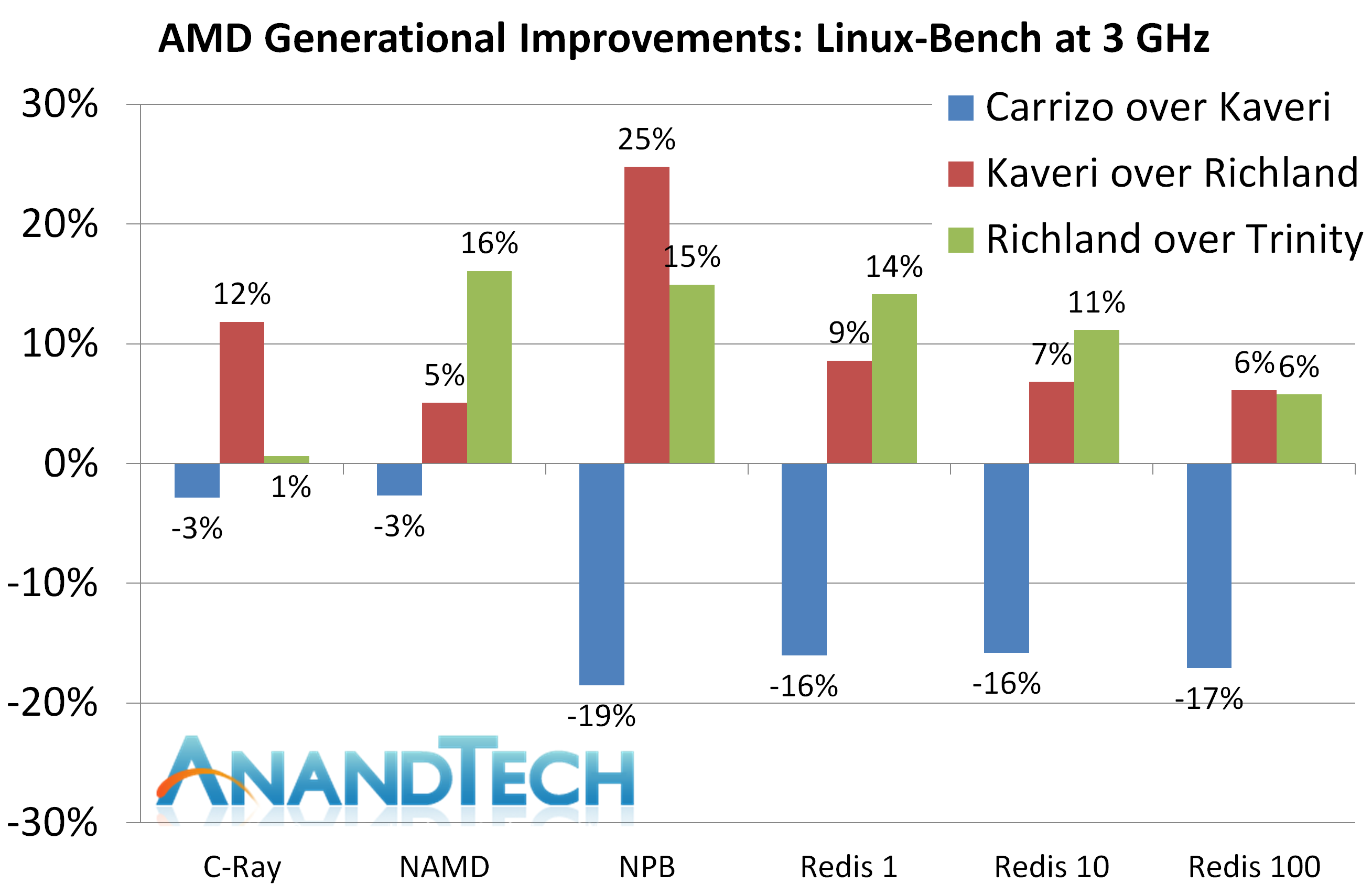
3Ghz Linux性能
C-Ray

NAMD, Scalable Molecular Dynamics

Kaveri有少许领先。
NPB, Fluid Dynamics

Redis



Carrizo的2M L2次次中枪。
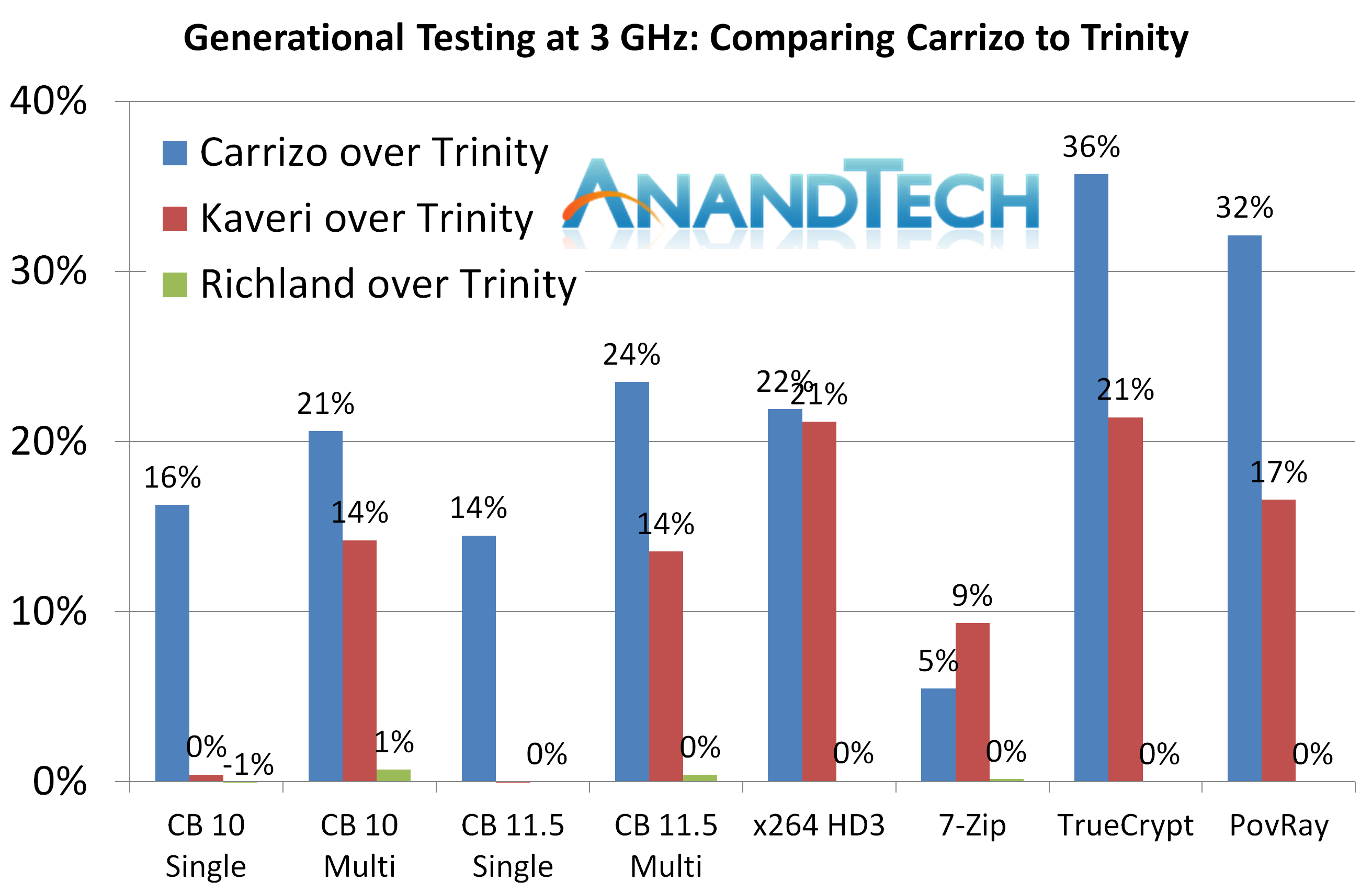
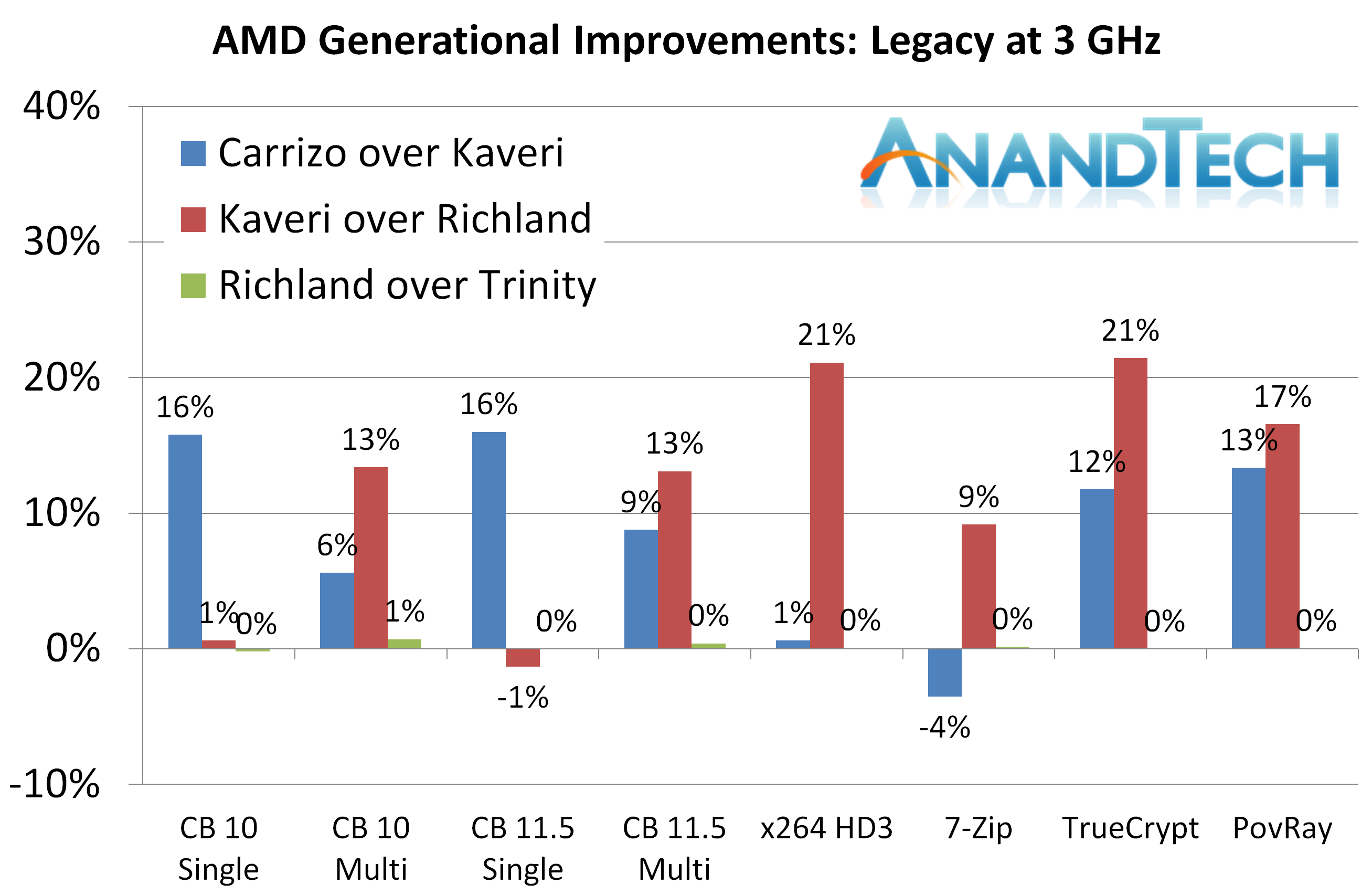
3Ghz 传统测试
3D Particle Movement v1


Carrizo有少许单线程提升,在多线程中增加了缓存压力,Carrizo立刻掉了下来。
Cinebench 11.5 and 10




Carrizo相对于之前的架构有明显提升。
POV-Ray 3.7

Carrizo相对于Kaveri提升13%,相对于Trinity/Richland提升达到了32%。
TrueCrypt 7.1

Carrizo的AES性能有明显提升。
x264 HD 3.0


使用稍微老一点测试工具就表明当帧很小的时候,就成为了Kaveri和Carrizo的性能瓶颈。(相对于Trinity依然有20%提升)
7-zip

我想知道如果Carrizo能有4M L2该多好。。
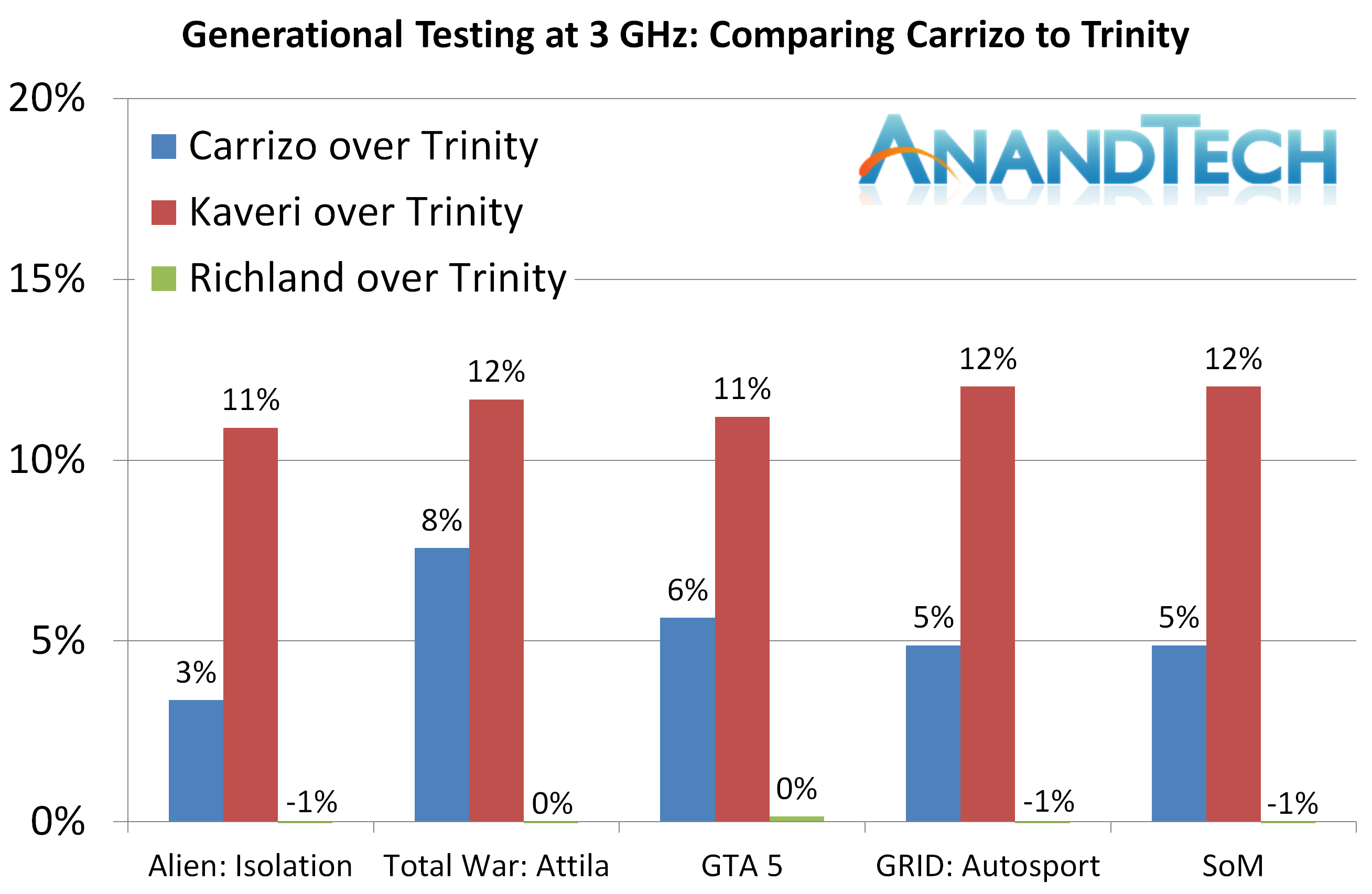
Alien: Isolation
显卡及其设置






每个项目Kaveri都超过了Carrizo,主要是L2的锅。
Total War: Attila at 3 GHz







和上个测试一样,Kaveri依然领先Carrizo。
Grand Theft Auto V







如果看平均帧,Carrizo性能在Trinity和Kaveri之间,落后Kaveri 3-7%。




看低于60FPS的时间,Kaveri再次领先。低端显卡比较有趣,对新架构更友好,但依然更偏向于Kaveri的4M L2。
GRID: Autosport












很明显,A卡在这里被黑的很惨。
Middle-Earth: Shadows of Mordor








从结果来看不能简单地说是L2或者PCI通道的瓶颈。
解析
简而言之,Carrizo在跑测试软件时领先Kaveri,而插独显跑游戏时就弱于Kaveri,特别是对内存和缓存增加压力时。本来笔记本马甲的这款U来到桌面玩游戏就是很蛋疼的事情,但Carrizo的架构的确有很大提升。
比较: 2012到2016的提升
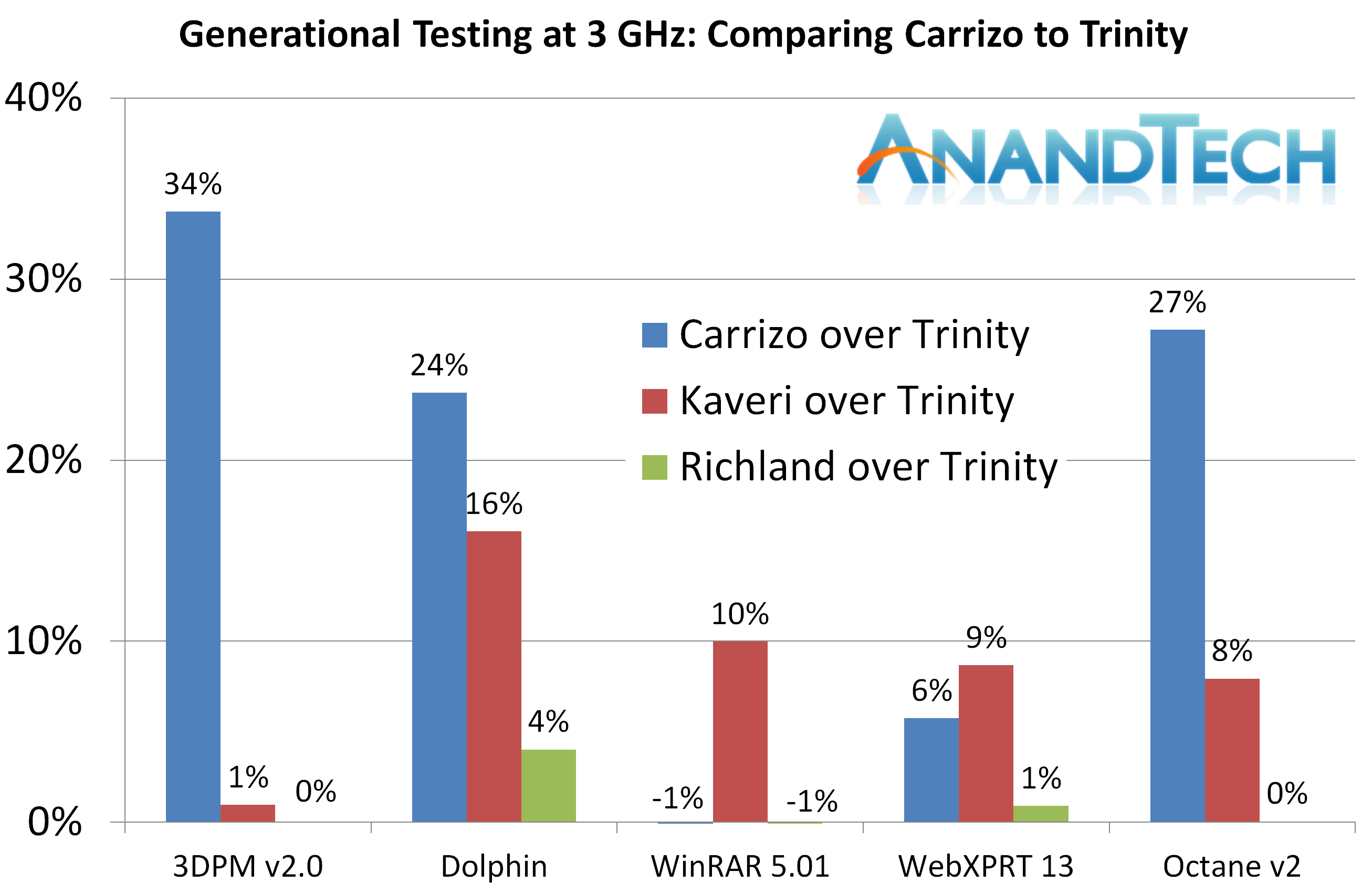
我们准备从两个方面来解析测试结果。首先,来看每个处理器相对于最老的Trinity的提升,这直接可以看出2012-2016年间每代的架构性能。

在实际性能测试中,Carrizo有三项大幅领先Kaveri,然而在WinRAR和WebXPRT却小幅落后。

办公测试中最大的提升在CineBench和Handbrake,在Photoscan和Hybrid中倒退。

Linux测试中每项Carrizo都倒退,甚至在三项Redis测试中落后于Richland。原因已经解释过了,Redis非常依靠内存和缓存,虽然Carrizo有更大的L1,仅有的2M L2造成了瓶颈。

这里很有趣。如果只看综合传统测试,像其他大多数测试网站得出的结论一样,Carrizo大幅领先Kaveri,有10-20%之多。

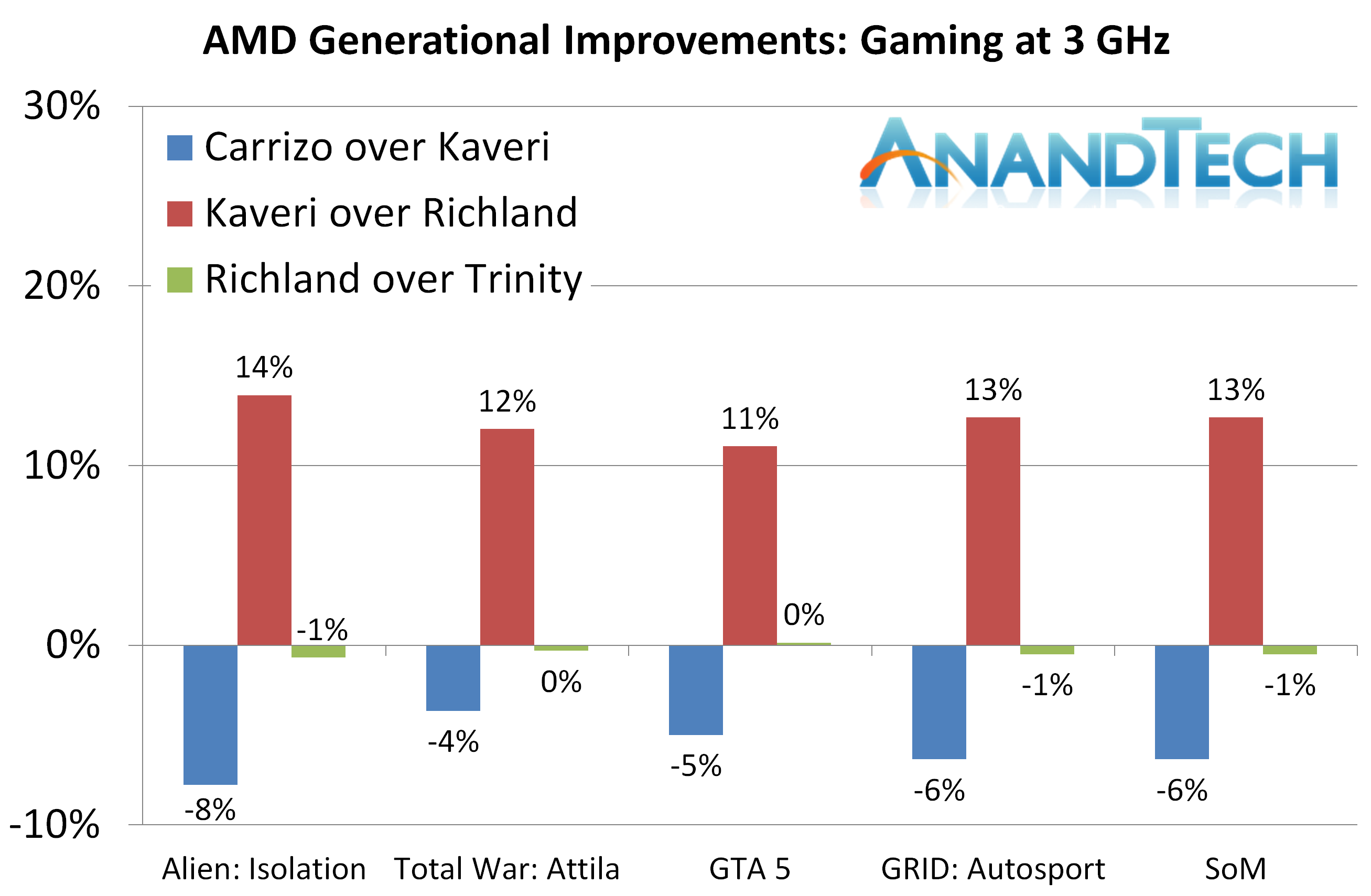
虽然Carrizo相对于Trinity有提升,但L2的砍半导致了游戏性能一直不如Kaveri。
比较IPC
然后我们比较从Trinity到 Richland 到 Kaveri 到 Carrizo的提升。一位数的提升为正常的架构换代,两位数的提升则为大幅改进或者新的功能模块。

3DPM v2有最大的提升。超过Kaveri 32%。这要归功于内存管理和更大的L1。 WinRAR依赖内存和缓存,Carrizo败在了砍半的L2。

办公测试比较复杂,在Photoscan中有倒退,因为很依赖缓存。但很明显,Kaveri的提升比Carrizo要大的多。

Linux测试很惨,每个测试Carrizo都有倒退。

回到前面的传统测试表格,Carrizo在所有测试中都比Kaveri强,除了7zip。在CineBench中体现出了Carrizo核心逻辑部分改动带来的进步。

然而,在游戏上,Carrizo同频落后Kaveri 5.8%。
结论
把所有数字综合起来

提升最大的是CPU计算测试,也就是实际性能、办公和传统测试,Carrizo相对于前代Kaveri带来了7.3%以上的进步。然而在更依赖于缓存的Linux和游戏性能测试,倒退了6-12%。
功耗
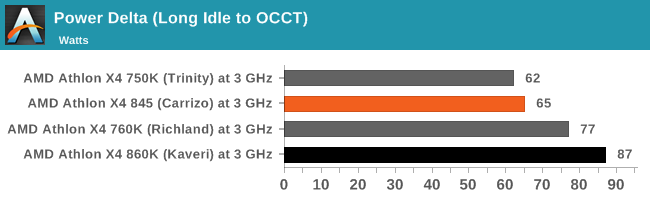
Carrizo的能效有正常水平的进步。
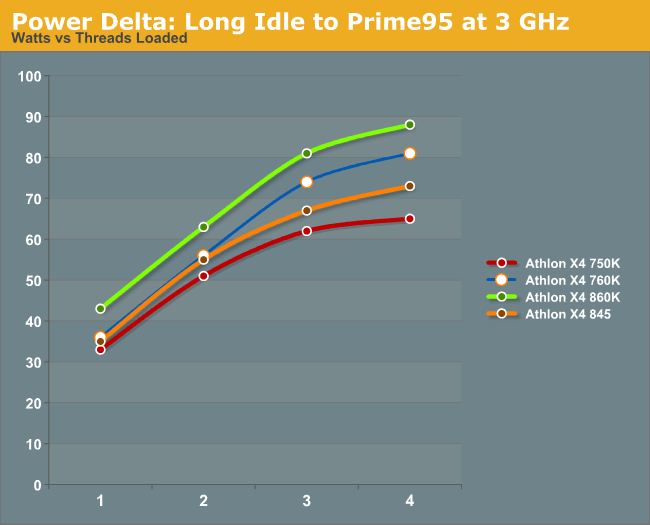
有趣的是每个模块的功耗。在开启第二个模块时,四款CPU的功耗都增加了大概20W,这是从单核变双核满载的情况。当开启第三、第四个核心时,很明显之前两个模块已经处于高频状态,所以开启同一个模块的第二个线程时,增加的功耗变小了。
超频
笔者的意见是,超频幅度非常非常非常有限。
外频调到120 MHz (35*120 = 4.2 GHz),一切正常,除了要上天的电压和八十多度的温度。内存频率保持2133。
再往上就很难了,121Mhz貌似是通过超频认证的上限。
但当我运行测试时,几次都宕机了,即便我提高电压也不行。
于是我把外频调回115,CPU再次罢工,这是之前稳定过的频率。之后调整电压也仅仅能通过部分测试。
外频调到110,也就是3.8Ghz,多数CPU测试通过了,但GPU测试依然无法通过。
这意思就是,我们的这块X4 845除了在默频能稳定工作,再往上就别想。
最后的最后,我在121外频得到了仅有的几个最基本的测试结果。




平均下来,超频21%带来了8-19%的性能。然而稳定性依然是个大问题,有几个测试重启几次才通过。




{kind=link}
{kind=link}
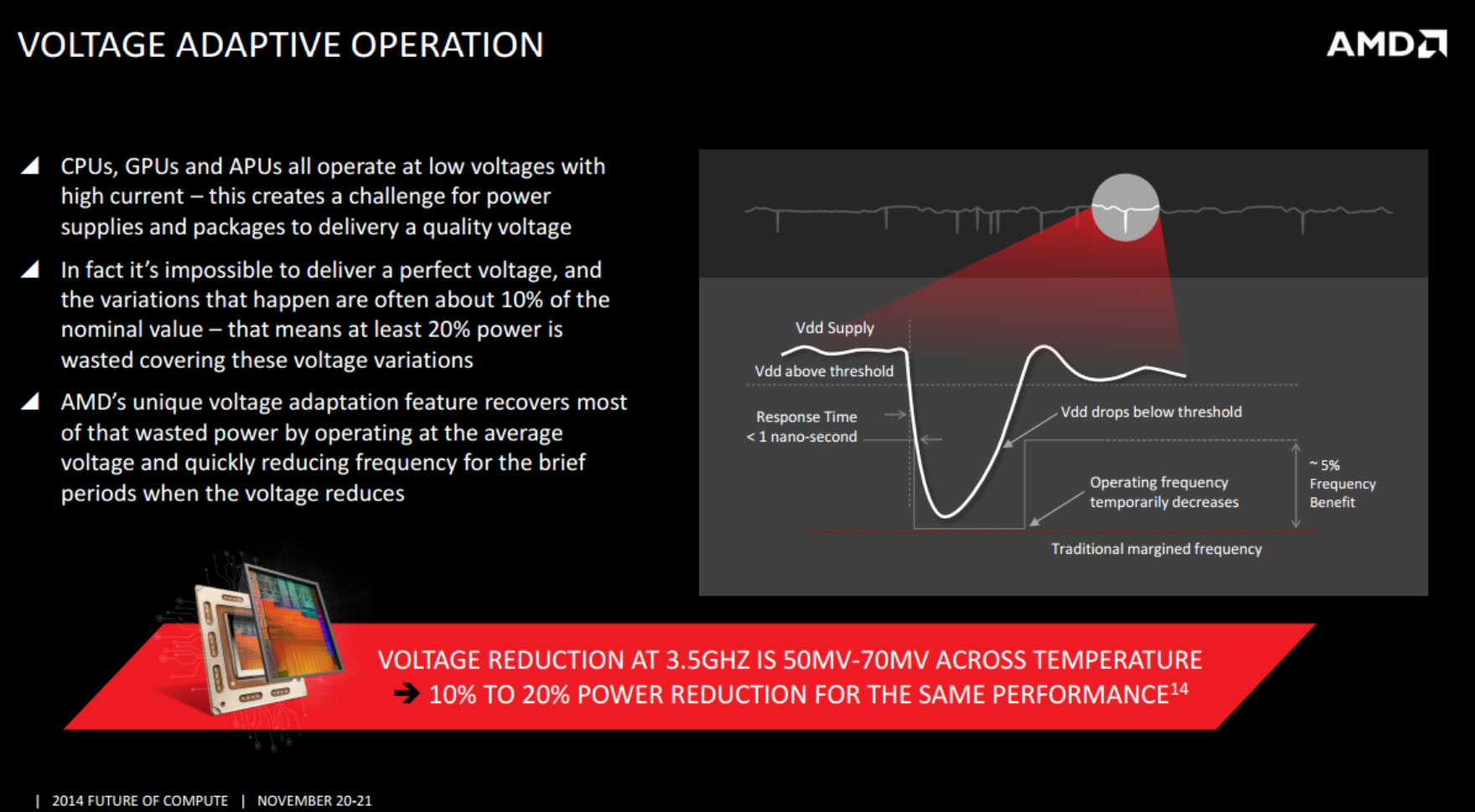{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}