2017.09.26:补全所有架构分析,包括Skylake-X以及Skylake-SP
本文地址:http://www.moepc.net/?post=2068
======2017.06.13更新======
Intel在放出价钱之后,又放出了具体出货日期,12核及以上依然没有任何频率和其他规格信息。
KabyLake-X 4核、Skylake-X 6-10核为6月26日开售,同时开始12-18核的预订【hehe…】
HCC阉割而来的Skylake-X 12核为8月开售
HCC部分的Skylake-X 14-18核10月开卖
Intel现场演示用i9-7980XE 演示《无人深空》VR
这个组合非常讽刺。

————-2017.06.02———————
一年半之前我们就开始等待HEDT版Skylake的到来,一直认为它会是对Broadwell-E的一次换代更新:加一两个核,涨一点价,换个新插槽,然后完事。然而Intel这次带来了“惊喜”:Skylake-X将把HEDT的核心数从10增加到18


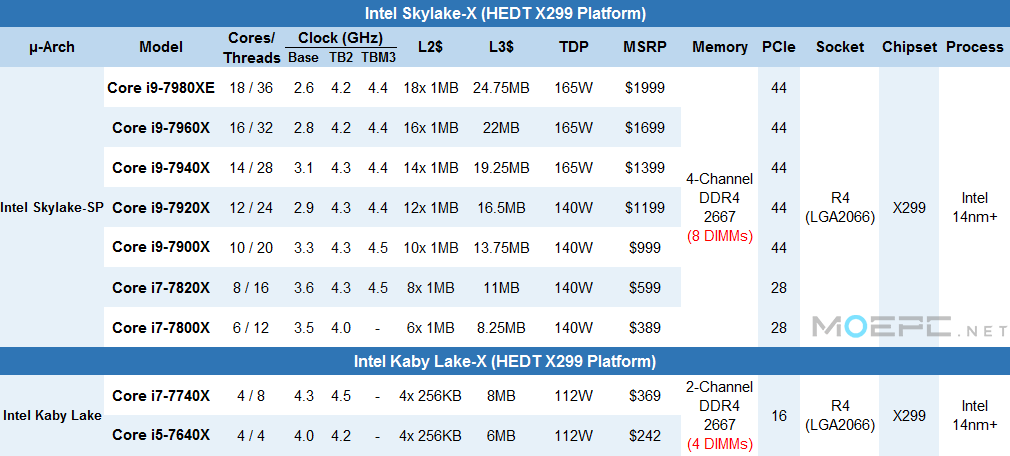
发布分好几个部分,首先是
Part1.低核心数 LLC Skylake-X处理器
上代Broadwell-E提供了4款处理器:2款6核,1款8核和顶级的1款10核。6核的两款差距主要在PCIe通道数上。这一代旗舰比上代Haswell-E多了2个核。
这个策略派生自Intel的“LCC” Low Core Count低核心数核心。Intel的企业级至强产品线有3种设计:低核心数、高核心数和极高核心数设计 – LCC、HCC和XCC。【上代是LCC/MCC/HCC,一个东西命名不同罢了。】所有至强都是这三种设计经过不同程度的阉割而来。对于消费级HEDT平台,比如HSW-E和BDW-E,都是LCC的产品。
Skylake-X阵容的前半部分与此相同,都是LCC核心。Intel将会发布4款LCC SKL-X,最多12核心。

最低端的是i7-7800X,3.5GHz默认,4.0GHz加速,不支持TBM3(TurboBoostMax3.0),6C/12T,四通道DDR4 2400,TDP 140W。
PCIe通道数只有28条,售价$389。这颗处理器属于四通道内存的入门级
然后是i7-7820X,在LCC设计中处于Sweet Spot地位。
8C/16T,3.6GHz默认,4.3GHz加速,4.5GHz TBM3(单核/双核),支持四通道DDR4 2666
但是与Intel通常策略不同的是,这款CPU的PCIe通道也被阉割到了28条。
正常情况下只有最低端的那款才会阉割,很明显Intel在核心数之外添加了PCIe这第二个分级因素。
TDP也为140W,售价$600,在这价位直接对手是Ryzen 7 1800X,IPC落后一代,但价格也便宜$100。

第三款则是新的Core i9系列的成员。之前我们有i3/i5/i7,现在Intel认为命名需要再加一层,i9这个命名就显得理所当然了。i9带来的明显“提升”在于PCIe从28条增加到了44条。

i9-7900X是目前唯一一款信息比较多的i9处理器:10C/20T,3.3GHz默认,4.3GHz加速,4.5GHz TBM3。支持DDR4 2666,140W TDP。这个级别Intel收钱基本是$100/核,所以价格是$999(零售$1049)
7900X是完整LCC。
IVB-E那代,旗舰6核需要$999;HSW-E的旗舰8核也是$999。到了BDW-E,Intel把旗舰级10核涨价到$1721,因为对应的企业级至强也是这价。至于SKL-X,新的价格策略又回到从前,10核售价$999,正是之前BDW-E旗舰6950X预计的价格。虽然不是旗舰,价格至少回到了合理范围。
同时i9-7900X也将是第一款能买到的i9,后续型号还得等段时间。
i9-7920X由HCC阉割而来,它将在今年晚些时候到来【八月?】,12C/24T的规格,售价$1199(同样按$100/核收费)。
据称Intel还在验证这款CPU的频率,想找到功耗和性能的平衡点,虽然按照我们理解它可能会变成165W而不是140W。
在企业级市场,前几代里Intel一直都有TDP异常高的处理器,这些通常称为“工作站”处理器【-W后缀】,用于单路或双路主板,并大幅提升频率和价格。7920X的性能、能耗比以及定价必须要合理。目前很多东西还没定下来,因为如果真拿出高频12核就可能影响部分至强的销量。
Part2.高核心数 HCC Skylake-X处理器
【规格?不知道。性能?不知道。发布时间?不知道。关心的理由?不知道。只知道名字,核心数和价钱而已。】
故事的转折点在于下面这批处理器。Intel出人意料地把HCC设计带到了消费级市场。
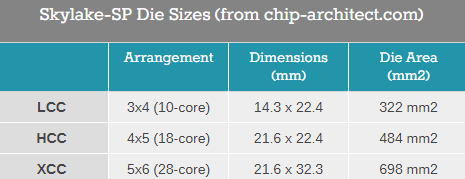
Skylake的HCC是18或20核。为什么说“或”,因为和我们原先预想的稍有不同。如果你半年前问我,我会说HCC是18核设计。前几年的LCC为单环形总线,HCC设计都是双环形总线(可能不平衡),为了平均每个核心L3的延迟。

上代E5V4 Broadwell-EP的设计
MCC=这代HCC
HCC=这代XCC。
下面是HCC SKL-X的设计


很明显有重复的部分:4×5,很像是20核+双环形总线设计。再仔细看最下面一排左数第二个核,颜色明显不同,这些是实际核心?还是因为支持AVX-512?或者不是核心,只是为了占地?我们向Intel提出过相关问题,不过到发布为止Intel都不会提供更多信息。
现在证实SKL-X使用类似于Knights Landing的“mesh”结构,不是之前的环形总线,而是一堆环形总线,那两个不一样的“核心”是IMC
下面是Intel计划发布的HCC SKL-X产品。

i9-7940X为阉割版HCC,14C/28T,散片售价$1399,依然每核心收费100刀;实际零售价应该在$1449-1479。
应该也是DDR4 2666,44条PCIe
7960X为16C/32T,散片售价1699刀(零售$1779?),应该也提供DDR4 2666,44条PCIe的支持。

i9-7980XE作为“光环”级旗舰产品,提供18C/36T,售价$1999(零售~2099刀)。现在这个点,没人知道这款什么时候能开卖。我估计就连Intel自己都不清楚。
解析:为什么现在提供HCC处理器?
Threadripper是AMD的HEDT处理器,提供16C/32T。Ryzen 7与BDW-E竞争的时候,Threadripper没有直接竞争对手,除非把至强考虑在内。
澄清一点,整个SKL-X并不是对Threadripper的回应。Skylake-X,基于我目前的理解,原来只有LCC:最多12核,就这样,安好。与Ryzen 7相比,BDW-E有核心数、缓存和IPC的优势。Intel有最好的,可以坐地起价。($1721的6950X和$499的1800X哪个更值,全取决于你的钱包)业界的几乎每个人,至少是我交流过的那些人,也抱有相同的期待。Intel本应发布LCC Skylake-X,最多12核,保持差不多定价,然后坐享其成。

在5月初FAD上AMD宣布Threadripper的时候,我怀疑当时Intel可能瞬间爆炸(如果在之前没有的话)。如果AMD拿出16核给消费级,就算IPC比Intel低个几个百分点,还是应该比Intel的LCC 12核要强的,12核就不再会是“光环级”产品。
当然还有一些其他因素,目前我们还不知道Theradripper的详细规格,而且Intel也有更大的生态系统,友商更多。
Intel卖掉了大量顶级HEDT处理器。就算10核$1721的6950X卖得最好我也不会感到惊讶。所以如果AMD拿到了性能王冠,Intel就会失去它保持了10年的性能宝座。
所以想象一下Intel当时全速运转的状态。他们会想到什么?用性价比竞争?提升频率?在以前频率竞赛年代你大可以搞一款高TDP的新处理器,挑下体质好的。在现在核战争的年代,如果IPC领先不多,你就需要实际的物理核心来提供更好性能。所以我估计Intel就只有下放HCC芯片这一条路好走。

当然我也推测Intel内部有过争论。HCC/XCC至强是Intel服务器的主要收入来源。把这些下放到消费级的话,中小企业为了节省大量开支就可能投奔消费级平台,而这些人占了服务器市场的不少份额。
Intel也没法把HCC处理器按企业级的价卖。
HCC可能是最好的选择,Intel依然可以卖出许多高端处理器,但营收会从企业级转向消费级。同时也能击退AMD的任何威胁。
Intel有2款CPU对抗Theradripper:1699$的16核7960X,以及1999刀的18核7980XE。Threadripper设计为2xMcM Zeppelin die,单颗Zeppelin 95W TDP下能达到3.6-4.0GHz,所以190W的16核Threadripper应该也能达到3.6-4.0GHz,我们知道AMD的高端都是特挑的,所以在140W下实现3.2-3.6GHz也是很容易的。这意味着如果AMD把Threadripper定在140W 3.2GHz左右,这俩i9也应该在这附近。一般除了超高端工作站处理器,Intel不会把所有HCC处理器频率定这么高。
虽然SKL有IPC和能效优势,Intel还是得先发制人。另一个未知数是AMD的定价,如果Threadripper定价$999-1099怎么办?
个人意见,这两家都值得称赞。AMD带来改变,Intel升格竞争。过去好几年都没有这样的事情了。
(实际上我预测Ryzen 7会在$699,实际发布1700只卖$329让人意外)
AMD Threadripper是2xMcM设计,每个Zeppelin上为2个4核CCX。在Ryzen上,当一个核心需要另一部分缓存中的数据时,缓存到缓存的延迟不一致。
而Intel HCC设计上,依然使用双环形总线设计的话,也会有相似的问题。【现在证实SKL-X使用类似于Knights Landing的“mesh”结构,不是之前的环形总线,而是一堆环形总线】
这两个设计都类似于NUMA
都知道NUMA的优化很需要技巧,而且支持NUMA的软件基本都是企业级,消费级应用包括游戏基本没有NUMA代码,所以性能优化方面会需要一个过程。

HCC SKL-X

LCC SKL-X
在企业级领域,Intel的至强产品线用到了这3种设计,这代是从4核(LCC阉割)到28核(XCC)。企业级平台内存通道更多,支持ECC以及更高容量内存,支持多路,以及其他RAS功能。一般这些功能到了消费级平台都会屏蔽。
以前Intel只把LCC晶片拿来做HEDT,有以下理由:
1.成本:如果买家想要XCC就得花大价钱,Intel的高端销量不会下降
2.软件:企业级软件对多核有良好优化,系统也是针对性的打造。而专业消费级需要全平台都能用,多核优化也没有那么好
3.性能:核心越多频率通常越低,对于企业级环境很适合,但对于消费级来说需要更快的反应速度及更好的交互体验。
4.平台集成:更大的核心需要额外的设计规则,一般是功耗或者功能方面的。为了支持这些,专业消费级平台就需要额外的设计/成本,或者砍掉拓展性。
那么是什么让Intel把HCC带进了HEDT专业消费级平台?
很多人给出的回答指向了AMD。今年AMD发布了自己的HEDT平台Ryzen Threadripper,999刀的16核有些出人意料,而且当时在部分(如果不是全部)关键测试还击败了Intel顶级的HEDT处理器。消极人士可能提建议为了继续保持领先,让Intel转向HCC,即便定价是AMD的两倍。
当然,把企业级处理器转到消费级平台不是马上就能完成的,很多分析者称Intel已经考虑了很久:内部进行测试,然后看市场风向来决定是否实行。分析者还认为数月前Intel发布Skylake-X时,除了核心数没有公布其他规格是因为:如果原计划有这些处理器,按照Intel以前的惯例,在那个时间点规格应该已经确定下来了。很可能引入HCC原本就在进行中,只是把HCC转到零售的i9是后来的决定,为了对抗高端产品线突然出现的威胁。
现在的问题是上面那4条对HEDT用户是否都适用:
1.成本:把18核定到1999价位,对消费级处理器是史无前例的,可以观察消费者的接受程度。对Intel的专业级至强会有影响,因为同级的要卖到接近3500刀;但Intel阉割的刀数已经足够拉开价位:内存通道(4 vs 6)、多路处理器支持(1 vs 4),ECC/RDIMM支持(有 vs 无)。消费级平台得到的是超频能力。
2.软件:Intel自从上代HEDT引入了“超级多任务”的概念,让用户能在同时运行多个软件:视频编码、直播、内容创作、模拟器等等。现在的要点在于,即便软件不能完全用到所有核心,同时运行多个实例或者多个不同软件也不会影响速度。解决方法只是把问题重新定义了,其他的什么也没做。
3.性能:与企业级处理器不同,Intel在HCC SKL-X处理器上提升了频率。基础频率略低,但加速频率高出许多,还有对TBM3的支持。缺点在于功耗方面。
4.平台集成:Intel通过将9款处理器3种不同设计放在同一个消费级平台,“解决了”这个问题。KBL-X和SKL-X的供电方式不同,内存支持不同,PCIE/IO数量也不同。起初发布时就有很多认为这会使平台过于复杂,会让人搞错(在我们测试中就搞坏了颗CPU)。
观点:为什么把“平台”PCIe也算上(并用在宣传上)很荒谬
处理器的PCIe数量,在我的记忆里,一直都是直接从PCIe根控制器里出来的,提供完整带宽,延迟也最低。现代系统中指的是处理器自身,更早一点的时期是指北桥。按此标准,intel主流处理器有16条,Ryzen有16或20条,Intel HEDT处理器有28或44条,AMD Ryzen Threadripper有60条。
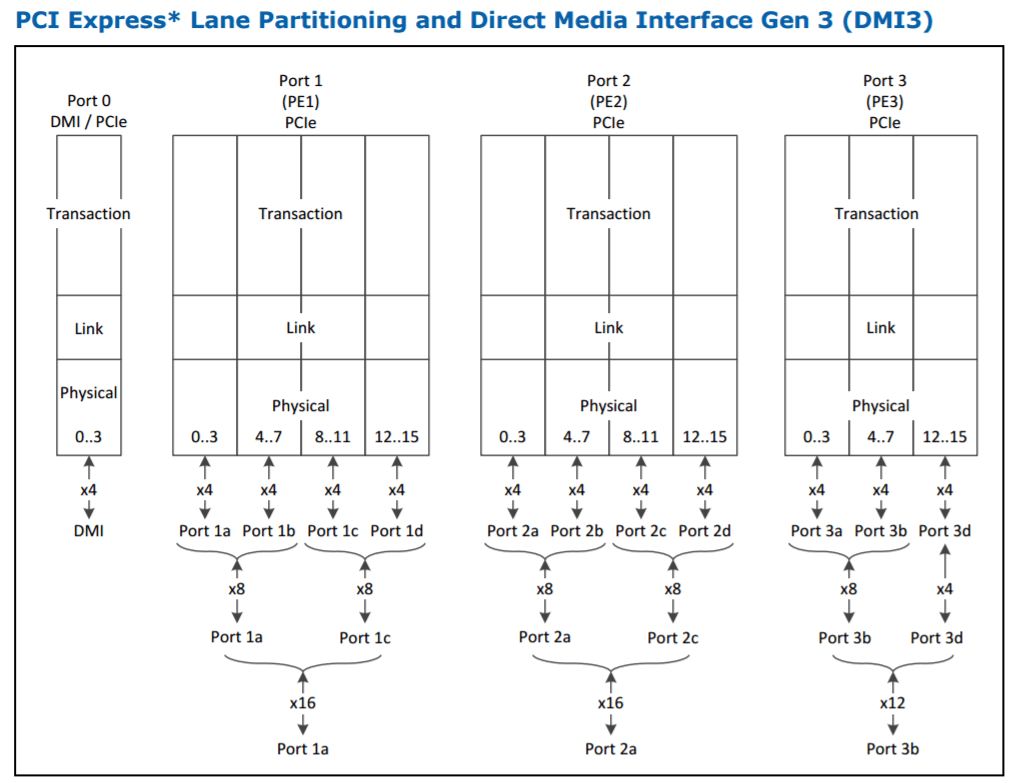
Intel的文档里,清楚地列出了处理器PCIe根复合体出来的PCIe:上面是从2个16条以及1个12条PCIe的复合体里出来的44条PCIe通道。连到芯片组的是披着DMI3之名的PCIe 3.0 x4,但不包括在这44条里。
芯片组的PCIe则与此不同。芯片组是各种用途的PCIe交换:使用有限的上行带宽,为低带宽控制器(比如SATA/网络/USB)进行通信。AMD在这方面稍弱,为了提升竞争力重返市场,在纯CPU性能方面投入了更多精力,就把设计外包给了ASMedia。Intel近3代处理器以来就在增加芯片组支持的PCIe通道数,现在支持最多24条PCIe 3.0。虽然关于哪些通道支持哪种控制器有额外的说明,但总的来说还是算作24条。
由于共享PCIe 3.0 x4上行带宽,芯片组(AMD和Intel)的PCIe通道很容易就会瓶颈。绕道芯片组比直连延迟更高,也正因此重要硬件(显卡、RAID控制器、FPGA等)很少会连在芯片组上。
CPU和芯片组PCIe的区别导致平台功能和配置上的不同。比如X399平台CPU有60条PCIe,以下是推荐的配置组合:
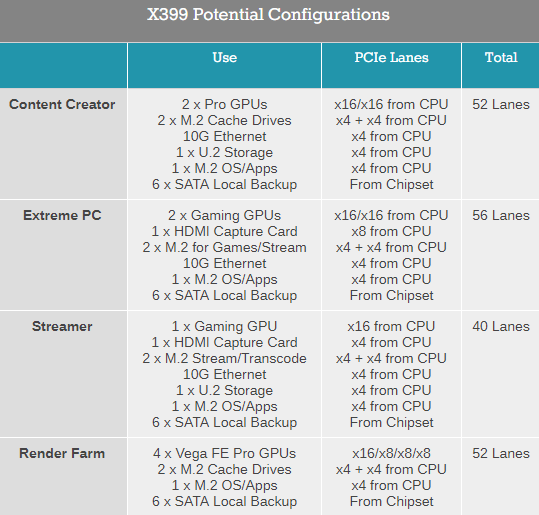
现在Intel和AMD都开始把CPU和芯片组的PCIe算在一起,在宣传时候数字显得大一些。这直接无视了不同PCIe之间的差异,为了宣传这两家也顾不了这么多。比如Intel就把新的Skylake-X处理器宣传成“68条平台PCIe通道”,在CoffeeLake里也宣传为“40条PCIe”。
我想把这种现象扼杀在萌芽状态:说好听点是误导,说难听点就是欺骗,主要因为在过去这个参数都是指CPU PCIe(于是每个人都会忽略“平台”两字)。仅仅因为厂商想让数字看起来更好看,也不意味着他们有权利重新定义并误导消费者。
举个栗子:大概4-5年前,在智能手机领域,厂商开始把主处理器的所有东西都算作核心,加起来作为“总核心数”。GPU核心被称为“核心”,ISP等特殊IP模块变成了“核心”,安全IP模块也被称为“核心”。本来CPU部分只有4核 A7,却说SOC有15核是很荒谬的。当然关注手机业界的人注意到这类胡扯很快就消停了,什么都能称作“核心”,即便是虚假的并不存在的核心 – 如果再继续下去,“核心数”这个参数就不再具有意义。
如果“平台PCIe通道”的概念继续搞下去,同样的事情将会重演。
Skylake-X的mesh 网格结构
Intel在8年后,终于准备摆脱环形总线了。
在2010年,Intel首次在Nehalem-EX上引入了环形总线,有效解决了核心/缓存间数据传输的问题
环形总线也是Intel这几年来架构的基石。
当时的8核已经算很复杂了,不好直接串起来
该举措的确是非常聪明的方法,双向低延迟高带宽的环形总线,还不占多大面积(占的是金属层)。


图源:PCWATCH
到后来的Broadwell-EP/EX上,核心数达到了22/24个,情况开始转变
可以看到LCC还只有1条双向环形总线,数据从1个核移动到距离它最近的相邻核需要1个周期,向更远的核移动就需要更多周期,这增加了额外的延迟。
由于每个核心都有各自的缓存区片,所以增加的延迟也会影响缓存性能。
如果是单向环形总线,数据移动到最远的核需要最多12个周期,所以Intel采用了双向环形总线降低延迟。
而在HCC处理器上就暴露出环形总线的最大问题 – 为了增加核心数,Intel不得不采用2条双向环形总线,这2条环形总线之间需要通过缓存交换(Buffered switch)。
交换会增加5个周期的延迟,然后数据继续向着目的地前进。增加的延迟限制了拓展能力,更耗电,消耗的热量也更多【想象一下核心更多的情况,延迟会怎样】
所以在核心数只多不少的Skylake-X上,Intel带来了“新的”mesh 网格结构
这结构并不是什么新东西,早在4年前的Knights Landing上就用过了。
而且上面清清楚楚地写着“Mesh of Rings”
是的,这玩意不是环形总线
而是一堆环形总线。


Knights Landing用一堆环形总线来组成“mesh” – 网格,只是每个环从原来的双向变成了4个方向 – 上下左右
“mesh” 网格结构的拓展性比环形总线强很多,72个核心的KNL就是例子,Intel只需要在中间加上更多核心即可
Knights Landing的数据移动方向是单向的:数据先在垂直方向上移动,直到它移动到正确的行上,然后再水平方向移动,直到命中正确的列。
环形总线运行在最高3GHz的频率,而Skylake-SP的Mesh以及L3运行在1.8-2.4GHz之间,意味着更高延迟
同时SKL-SP多出的核心会进一步增加延迟。
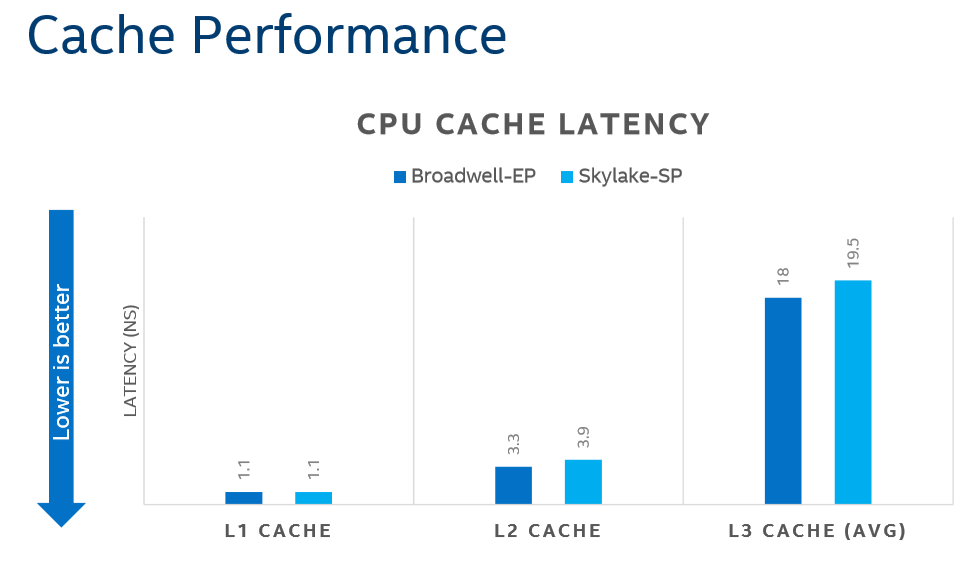
Intel声称L3延迟只增加了10%,同时耗电更少。
双环形总线的Broadwell-EP上平均延迟为6个周期左右,略好于Skylake-SP
Skylake-SP同一列两端的两颗核需要4个周期,而同一行两端需要9个周期;最差的情况,对角线需要大概13个周期。
这个数字还是比EPYC的MCM封装间通信要快很多。


28核Skylake-SP及“mesh”结构图
目前为止对于Mesh结构的褒贬不一。Mesh结构的拓展性比环形总线高,但没有环形总线那样经过十年以上的优化。而且有些用户指出Mesh的运行频率(通常为2.4GHz)在他们的软件里造成了瓶颈,因为原来的环形总线频率更高速度更快。Intel在今后几代应该会继续Mesh结构,比较关注会怎样进行改进。
Part.3 Skylake-X新的缓存架构
Skylake-S核心的32KB L1数据缓存为8路组关联,延迟为4个周期,每周期支持2x32byte读和1x32byte写:新的Skylake-SP中翻倍,Intel只说是“每周期128byte读和64byte写”,应该是2x64B读+1x64B写。
L2延迟比SKL-S略微增加,现在是13个周期
在前几代HEDT和Xeon处理器上,Intel采用了3层级缓存的架构。L1和L2为每个核心的private(私有缓存),且为Inclusive(包含式缓存);L3则作为LLC缓存,涵盖所有核心,也是Inclusive。总的来讲这相当于L2的所有数据在L3里都有一份拷贝,如果一个数据块被驱逐进L2,它也将存在于L3内备用,就不需要跑大老远访问内存了。同时缓存大小也很重要:L3是L2的包含式缓存的情况下,L3大小通常是L2的倍数,以便存储L2的所有数据再加上L3的额外数据。Intel自从第一代Core i(Nehalem)起就是每核心256KB L2,平均每核心1.5-3.75MB L3,L2和L3的容量及性能空间都很充足,而且L2距离核心逻辑部分更近。

在Skylake-X上,缓存设计有了改变。在Skylake-S发布当初,我们发现SKL-S的L2关联度有所降低,从Broadwell的8路组相连变成了4路组相连 – 带来了更多的模块性,在SKL-X上就用上了这一点。SKL-X每核心的私有L2增加到了1MB,为原来的400%,代价是砍了L3,从每核心约2.5MB减少到了每核心1.375MB。

L2已经这么大了,那么L3就不会再是L2的inclusive,现在变成了“non-inclusive”【介于inclusive和exclusive之间】,L3依然保有部分Victim cache所不具备的L3特性,比如预取。这也意味着在Snooping(监听)和追踪数据块位置方面要做出更多付出,核心将会监听其他核心的L2,寻找更新的数据(内存作为备份,数据可能过期)。前代的L3一直都是作为备份,现在情况不同了。


图源:沧者极限

Xeon Gold 6130的缓存 图源:InstLatX64
这样设计的好处在于大容量L2会提升命中率,降低未命中率。
取决于组关联度【根据测试应该是16路组关联】,一般情况下2倍缓存容量能够将缓存未命中率降低2的平方根(1.41)- 变为原来的70%,在通常应用中带来3-5%的IPC提升。
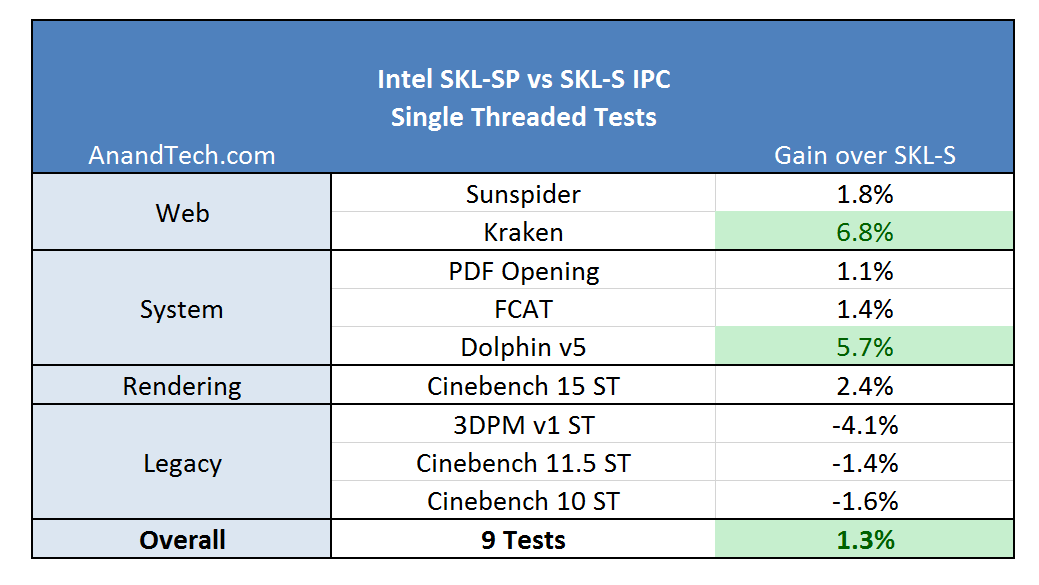
那么在SKL-X上:L2的未命中率将为原来的约49% – 命中率变为原来的200%,IPC提升8-13%。虽然除了缓存之外的架构都没变,但SKL-X和SKL-S的性能会不同。
测试的IPC
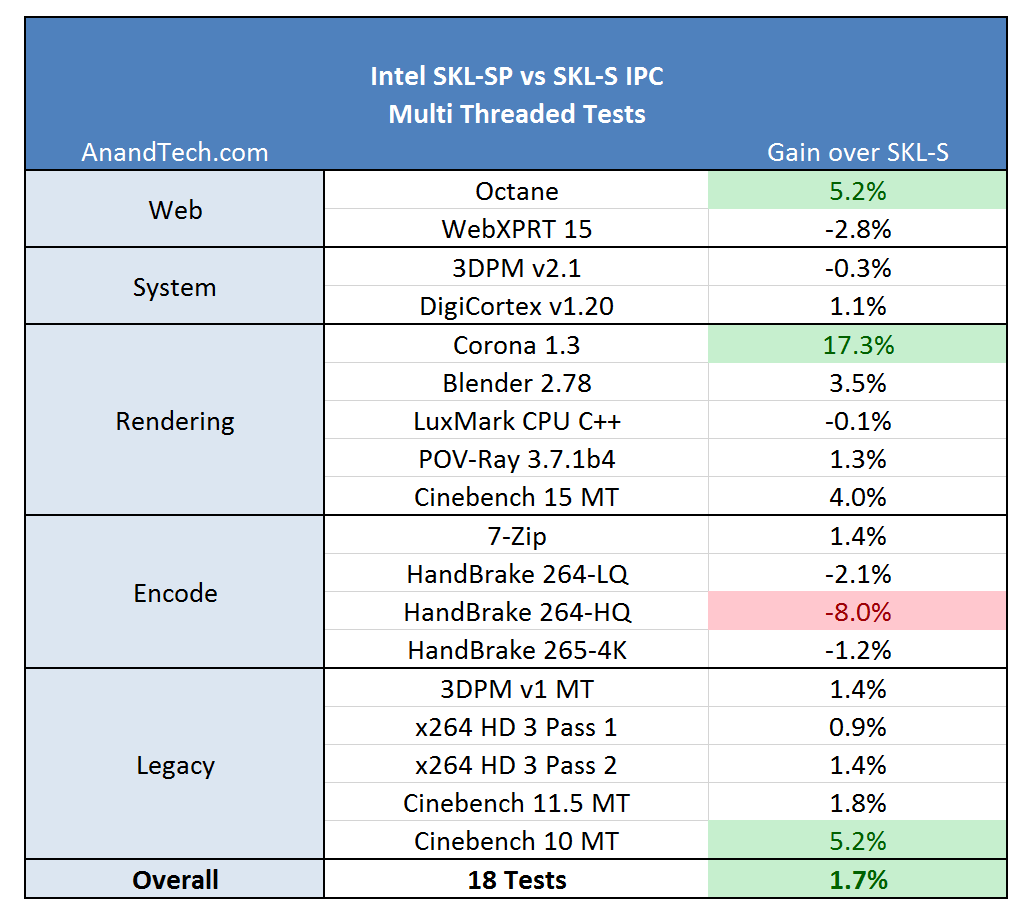
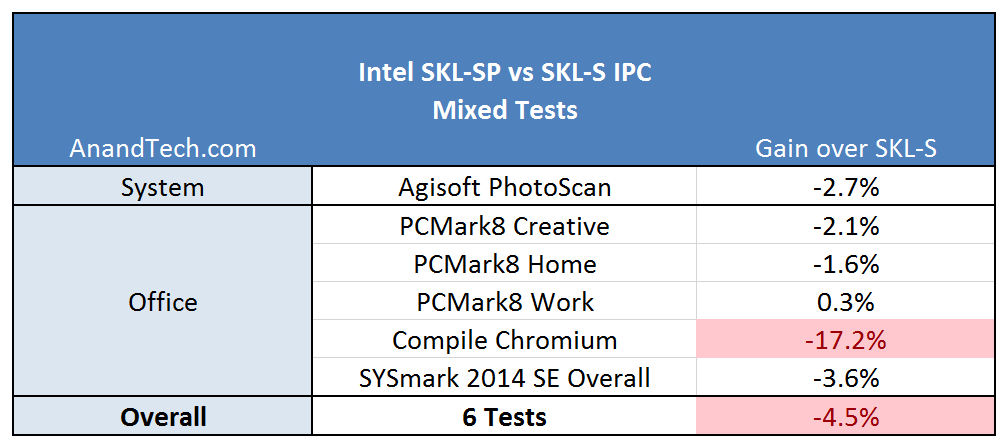
Ian一开始的想法是缓存布局不变,只是将原来的部分L3设计成L2。这样情况会比较复杂,有部分L2的延迟就和L3一样,如果L2延迟不一致会带来很多麻烦。这个方法虽然只用在原有设计上稍作改动,实际实施起来却很难。
根据PPT上HCC SKL-X的die shot,很明显L3没有涵盖所有核心,而是分块的。而且现在每核心的L2和L3容量也差不多,根据这两点事实Ian怀疑SKL-X就是用的1MB L2,能带来高命中率和持续的低延迟访问。
Part.4 AVX-512/Favored Core
首先是Skylake-X上对AVX-512的支持。Intel在上代Knights Landing Xeon Phi处理器上引入了AVX-512(至少是某种变种),在SKL-X上是首次将AVX-512带入消费/企业核心领域。
Xeon Platinum 28C
i9-7XXX,18C
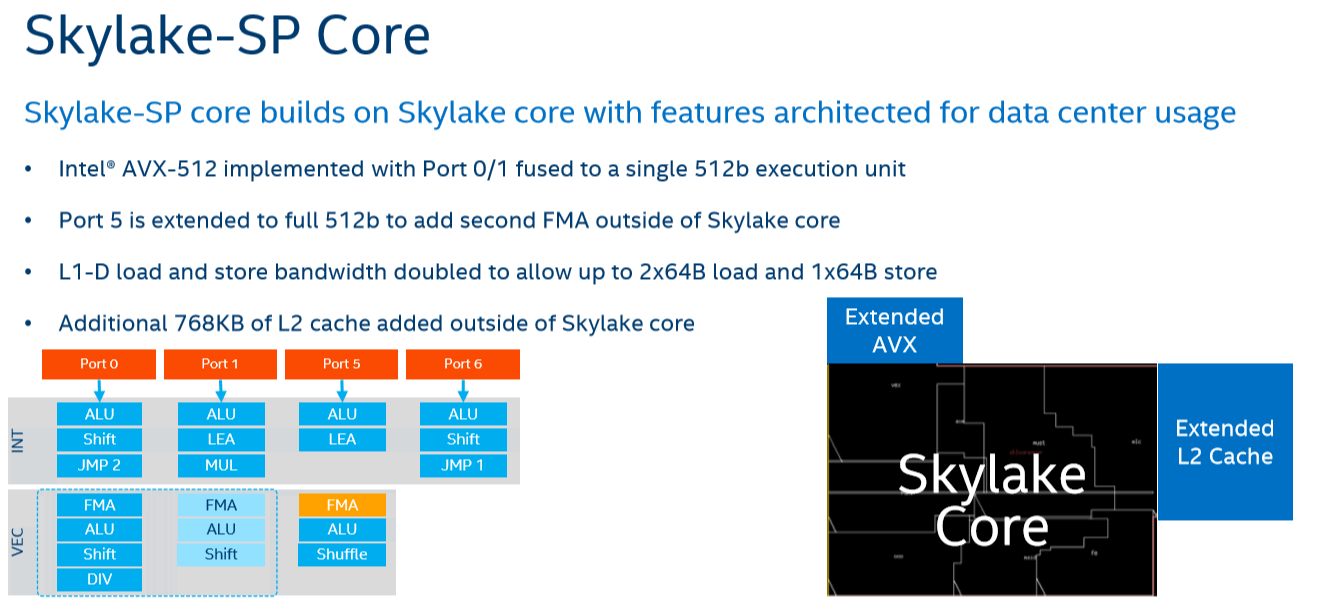
SKL-X的端口配置,端口0,1的FMA为256bit,执行AVX-512-F是两个端口合并的,与KNL类似。
端口5在Skylake核心外加了第二个FMA,只支持AVX-512。
Intel称6核及8核的LCC Skylake-X生产时就屏蔽了port 5,有少数报告称检测到port 5没被屏蔽。
意味着10核7900X每周期支持64次单精度或32次双精度运算,6核/8核为32次单精度或16次双精度运算。
很显然为了marketingIntel会强调AMD Zen核心只有俩128b FMAC,而Skylake-SP有俩256b FMAC以及1个只能用于AVX-512的512b FMAC。
纸面上看AMD的劣势很大,256b AVX2.0指令的数据量是AMD的两倍,如果用上AVX-512,Intel将可执行32次双精度浮点运算,AMD的4倍。
另一方面现实是,刚出不久还比较复杂的AVX-512 ISA需要很长时间才能被大部分软件所采用。最好的结果会在昂贵的HPC软件上,开发商(比如Ansys)会让Intel工程师干苦活:HPC软件要通过费时费力的人工优化才能很好地支持AVX-512。同时其它严重依赖Intel优化良好的MKL的软件也会有明显提升,比如Linpack。
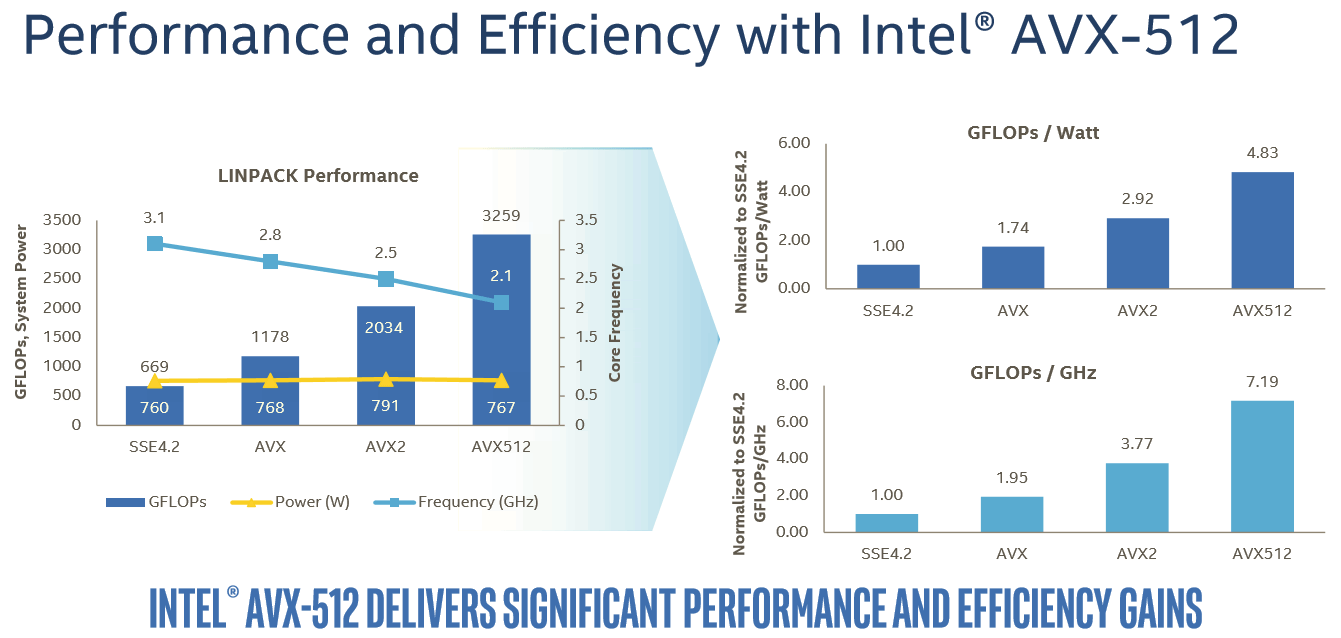
Intel称性能提升了60%。
对于普通用户,编译器目前还无法生成比目前更快的AVX-512代码,即便如此,提升也很有限。就算是最好的情况下,性能提升也会因AVX-512单元的低频率打折扣。

比如Xeon 8176全核可以达到2.8GHz,AVX 2.0下为2.4GHz(-14%),
执行AVX-512时频率大幅降至1.9GHz(-33%)。
所以即便是优化良好的代码,AVX-512也不会给你两倍性能。
非AVX/AVX2.0/AVX-512加速模式频率对比
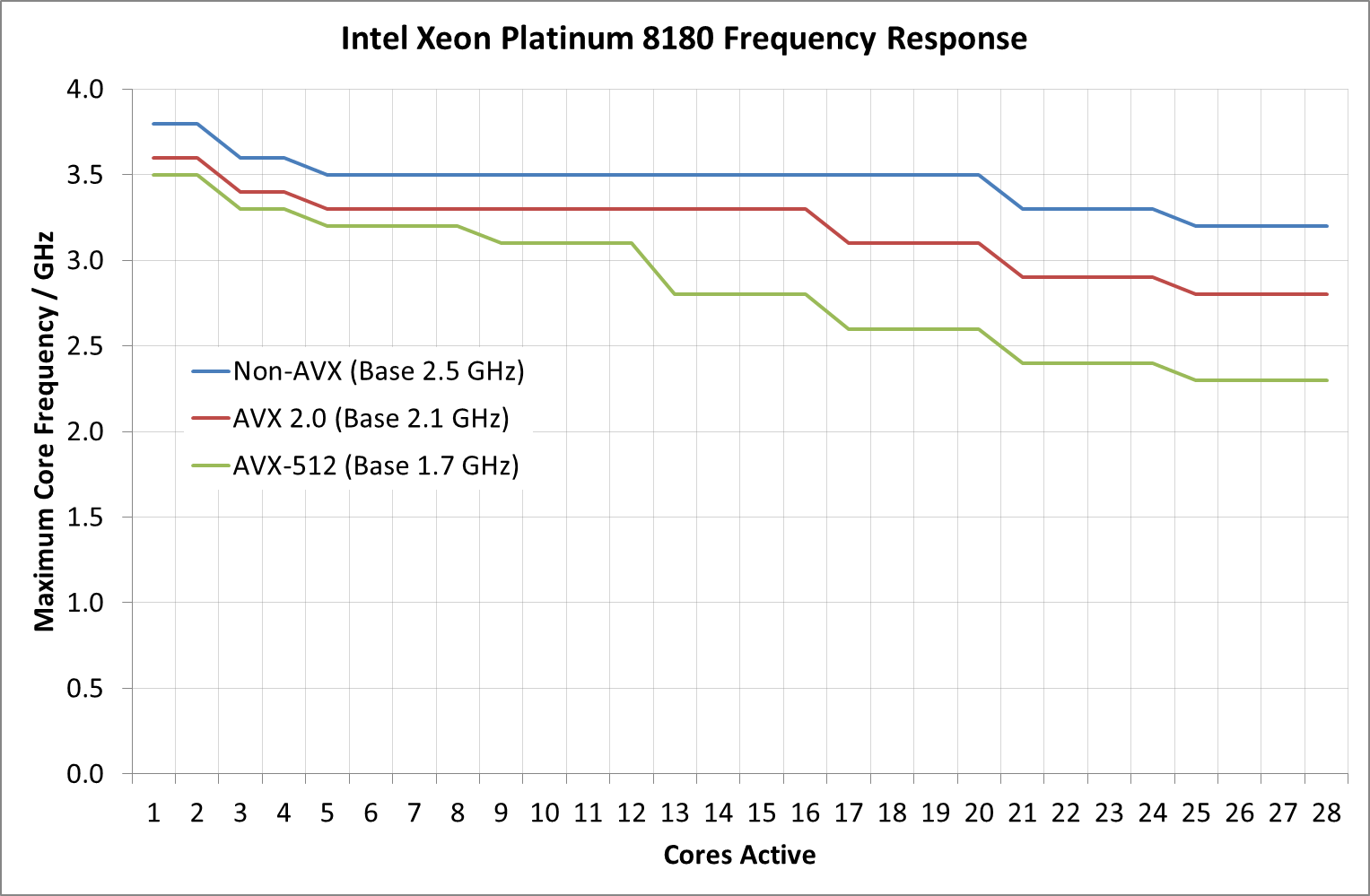

非AVX加速频率表
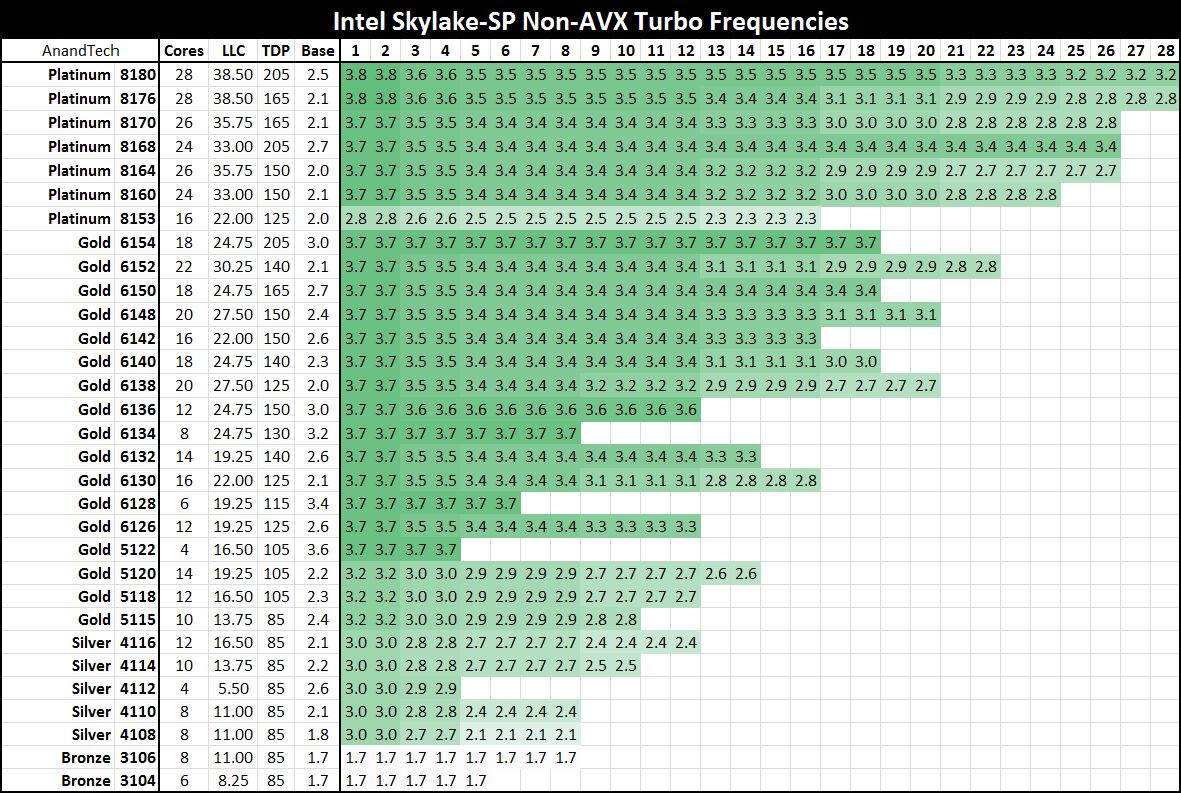
AVX2.0加速频率表

AVX-512加速频率表
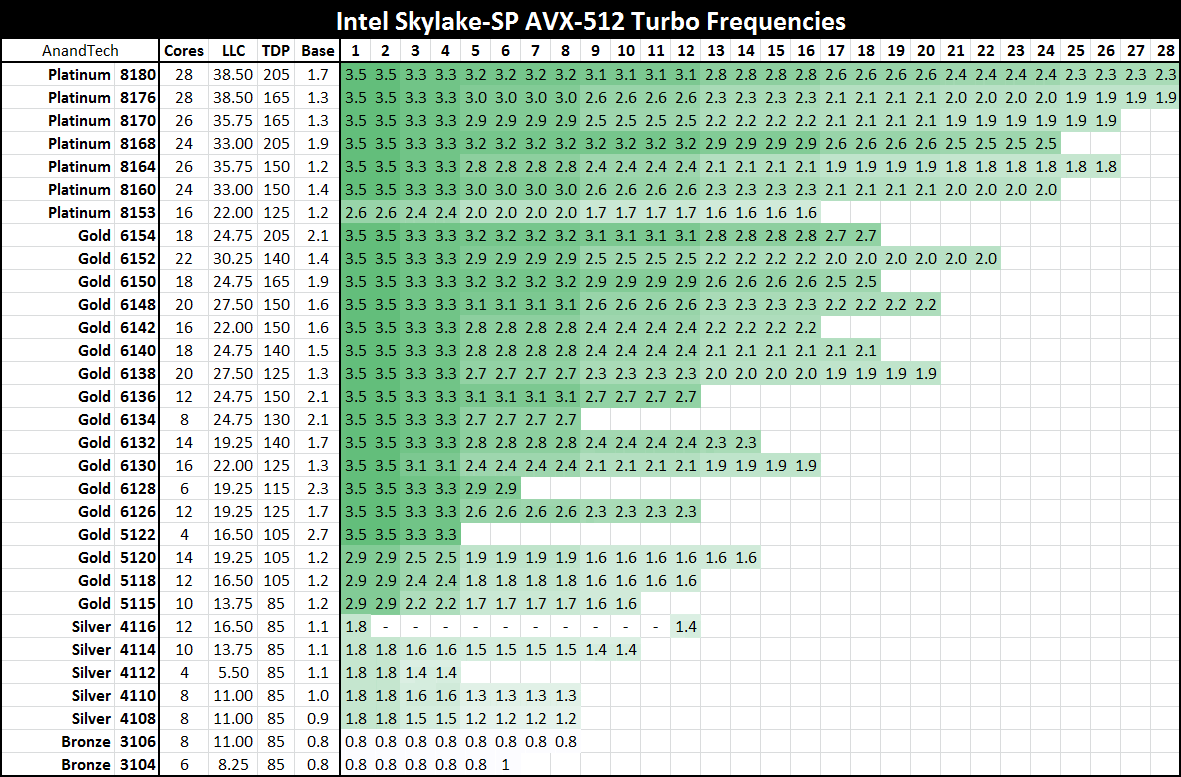
Skylake-SP的AVX-512单元支持范围很广,只要编译器出来了,可以轻松将通常的代码导入到AVX-512,比以前SSE导入AVX容易得多
Intel想让软件商利用编译器提升性能,主要目标还是企业市场,导入一般软件还需要一段时间。
与AVX/AVX2一样,AVX512的目标是提供强大的硬件来解决向量计算。AVX单元耗费很多晶体管,密度很高,所以持续的计算会产生大量热量:支持AVX/AVX2的Intel处理器在运行AVX指令一般会降频,AVX512也没有两样。Intel没有揭晓执行AVX-512指令时的运行频率,如果每个核心都支持AVX-512,那么降频应该只会影响那单个核心。
有了AVX-512,Intel将i9-7980XE称为首个TeraFLOP CPU,具体计算方式未知。AVX单元和GPU一样可以计算向量,以独立硬件单元完成并行计算 – 传统通用CPU和其他硬件的界限正在变得模糊。
AVX-512的不同指令:
AVX-512-F: F for Foundation
AVX-512-BW: Support for 512-bit Word support
AVX-512-CD: Conflict Detect (loop vectorization with possible conflicts)
AVX-512-DQ: More instructions for double/quad math operations
AVX-512-ER: Exponential and Reciprocal
AVX-512-IFMA: Integer Fused Multiply Add with 52-bit precision
AVX-512-PF: Prefetch Instructions
AVX-512-VBMI: Vector Byte Manipulation Instructions
AVX-512-VL: Foundation plus <512-bit vector length support
AVX-512-4VNNIW: Vector Neural Network Instructions Word (variable precision)
AVX-512-4FMAPS: Fused Multiply Accumulation Packed Single precision

Intel处理器对AVX-512的支持,图源InstLatX64
Favored Core
上代Intel HEDT平台Broadwell-E上Intel引入了Favored Core,也被称作“Turbo Boost Max 3.0”。原理是生产线上下来的每颗CPU都不同(即便同型号),每颗CPU内部的不同核也会有不同的电压/频率特征。能达到最高频率的那个核就被称为“Favored Core”,当Intel的WIN10驱动软件到位后,单线程负载就会被移到这个核上,运行更快。
理论上很美好 – 单线程比传统的睿频频率要高100-200MHz。但实际上就不那么好了:主板厂商没提供支持,或者BIOS里默认是关闭的。
而且买家还要装驱动和软件,少一样就没有作用。

在Skylake-X上Intel也做了改动,驱动和软件变成了WIN10更新的一部分,所以买家自动就会被安上这些。
Skylake-X上的TBM3也从单核变成了双核。
何时出货
KBL-X/LCC SKL-X预计在6月
12核7920X估计在8月
至于14/16/18核影都没有,只会更晚。
Intel只放了个价格给你们看看罢了

via:anandtech/Twitter/网络搜集
基于http://www.anandtech.com/show/11464/intel-announces-skylakex-bringing-18core-hcc-silicon-to-consumers-for-1999
原作:Ian Cutress
部分信息来自网络
AVX-512:InstLatX64
Mesh结构:Semiaccurate/TomsHardware
本站编译,转载请注明出处。
本文地址:http://www.moepc.net/?post=2068




听说7980XE Turbo Boost Max 3.0能到4.5GHz。。。
@1311abcd11:单核
马文威武!!!
哈哈哈No Man’s Sky,没人(买得起)的Sky(lake)
@ssnitrousoxide:gg
You’ve got it
amd一脚踩在牙膏管上
最便宜tr16core $849
INTEL 环形总线
AMD RYZEN 又是什么总线
@青之淘:IF总线
@Origin:超能网的编辑Origin?
7800x是和1700的对位产品吗?
还有能不能做一期,Intel环形总线的讲解?
怎么缓存和AVX-512没有下文了?
@Ayu:更新了